Transformerの学習済みモデルをLambdaにデプロイする(SAM)
前回もTransformerの学習済みモデルをLambdaにデプロイしましたが、別の方法を試してみます。
Transformerの学習済みモデルをLambdaにデプロイする
前回、flask で作ったAPIをChaliceを使ってLambdaにデプロイしてみました。 この方法は、アプリをzip形式でアップロードします。zip形式は、最大250MBのサイズ制限があり…

今回は、AWS Serverless Application Model(sam)を使っています。
同じ目的であれば、やる必要はない様にも思えるのですが、どちらの方がいいのか試してみたくなりました.
結果としては、AWS SAMを使った方がわかりやすく、今後はこちら(SAM)を採用することになるだろうと思います。
SAMを使ったデプロイに関しては、以下のYoutubeを参考にしました。
この動画では、Hugginfaceのpipelineを使って、Question -Answeringモデルをデプロイしていますが、せっかく応答生成モデルを学習させたので、このtext2textモデルをデプロイしてみました。
AWS Serverless Application Model (SAM)
SAMは、いくつか質問に答えていくだけで、アプリケーションの雛形を作成してくれます。
事前準備
事前準備として、
- AWS SAM CLI のインストール
- AWS認証情報のセットアップ
が必要です。次の公式サイトを参考にしてください。
sam init
sam init コマンドで、インタラクティブにアプリケーションの雛形を構築をしていきます。今回は以下のような選択をしました。
$ sam init
Which template source would you like to use?
1 - AWS Quick Start Templates
2 - Custom Template Location
Choice: 1
Choose an AWS Quick Start application template
1 - Hello World Example
2 - Multi-step workflow
3 - Serverless API
4 - Scheduled task
5 - Standalone function
6 - Data processing
7 - Infrastructure event management
8 - Machine Learning
Template: 1
Use the most popular runtime and package type? (Python and zip) [y/N]: n
Which runtime would you like to use?
1 - dotnet6
2 - dotnet5.0
3 - dotnetcore3.1
4 - go1.x
5 - graalvm.java11 (provided.al2)
6 - graalvm.java17 (provided.al2)
7 - java11
8 - java8.al2
9 - java8
10 - nodejs16.x
11 - nodejs14.x
12 - nodejs12.x
13 - python3.9
14 - python3.8
15 - python3.7
16 - python3.6
17 - ruby2.7
18 - rust (provided.al2)
Runtime: 13 ※
What package type would you like to use?
1 - Zip
2 - Image
Package type: 2
Based on your selections, the only dependency manager available is pip.
We will proceed copying the template using pip.
Would you like to enable X-Ray tracing on the function(s) in your application? [y/N]:
Project name [sam-app]: text2text
Cloning from https://github.com/aws/aws-sam-cli-app-templates (process may take a moment)
-----------------------
Generating application:
-----------------------
Name: sample
Base Image: amazon/python3.9-base
Architectures: x86_64
Dependency Manager: pip
Output Directory: .
Next steps can be found in the README file at ./sample/README.md
Commands you can use next
=========================
[*] Create pipeline: cd sample && sam pipeline init --bootstrap
[*] Validate SAM template: sam validate
[*] Test Function in the Cloud: sam sync --stack-name {stack-name} --watch
※ランタイムを選択する際に、14. python3.8 を選択すると、テンプレートファイルが作成されないという現象がありました。13. python3.9を選択すると、問題なく作成されます。原因については調査しましたが、未解決のままです。
template.yamlの変更
実行環境の変更
# More info about Globals: https://github.com/awslabs/serverless-application-model/blob/master/docs/globals.rst
Globals:
Function:
Timeout: 300
MemorySize: 3008Timeoutと、MemorySizeを変更しています。一度、デプロイ後に実行してみたところ初回起動時のモデルを読み込み時に、Timeoutが発生しました。そこで、動画よりも少し長い目に設定し直しています。
Memory Sizeは動画の通りです。実際に実行してみると最大2800MBほど使っていましたので、妥当な設定かと思いました。

MemorySizeの3008MBは、過去、Lambdaのメモリ割当の上限値だったようです。現在は10GBまでとなっているので、必要に応じて増やすこともできます。ただ、コストに関係しておきますので、ご注意ください。
Resources:
HelloWorldFunction:
Type: AWS::Serverless::Function # More info about Function Resource: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#awsserverlessfunction
Properties:
PackageType: Image
Architectures:
- x86_64
Events:
HelloWorld:
Type: Api # More info about API Event Source: https://github.com/awslabs/serverless-application-model/blob/master/versions/2016-10-31.md#api
Properties:
Path: /text2text ※
Method: POST ※
Metadata:※にある、Pathと、Methodを変更しています。
HelloWorldApi:
Description: "API Gateway endpoint URL for Prod stage for Hello World function"
Value: !Sub "https://${ServerlessRestApi}.execute-api.${AWS::Region}.amazonaws.com/Prod/text2text/" ※
※にある、Valueを変更しています。
requirements.txt
requests
-f https://download.pytorch.org/whl/torch_stable.html
torch==1.8.0+cpu
transformers==4.20.1
sentencepieceHuggingFaceのモデルを利用するために、以下を追加しています。
torch==1.8.0+cpu
transformers==4.20.1
また、自作のモデルではsentencepieceを使っていますので、これを追加しています。
modelの追加
次に、動画では local_download.pyを実行して、HuggingFaceからモデルをダウンロードしていますが、今回は自作のモデルを使いますので、hello_worldフォルダ配下にmodel01フォルダを作成してモデルをコピーしておきます。
また、Dockerfileに、モデルのコピーコマンドを追加します。
FROM public.ecr.aws/lambda/python:3.9
COPY app.py requirements.txt ./
COPY model01 /opt/ml/model //追加
RUN python3.9 -m pip install -r requirements.txt -t .
# Command can be overwritten by providing a different command in the template directly.
CMD ["app.lambda_handler"]app.pyの変更
メインの処理ですが、以前VPSで実装したflask アプリを参考に、以下のようにしました。
応答生成モデルの実装
構成の選択 一番最初の記事に記載した通り、iOSのアプリケーションから「発話」をテキストで送信すれば「応答」をテキストで返す様にしたいと思います。 このwebAPIを実装…

変更点は、イベントの入出力部分をLambdaに合わせたところのみです。
from email.quoprimime import body_check
import json
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("/opt/ml/model")
trained_model = T5ForConditionalGeneration.from_pretrained("/opt/ml/model")
def lambda_handler(event, context):
raw_string = r'{}'.format(event['body'])
body = json.loads(raw_string)
data = body['text']
MAX_SOURCE_LENGTH = 24 # 入力される記事本文の最大トークン数
MAX_TARGET_LENGTH = 24 # 生成されるタイトルの最大トークン数
# 推論モード設定
trained_model.eval()
# 前処理とトークナイズを行う
inputs = [data]
batch = tokenizer.batch_encode_plus(
inputs, max_length=MAX_SOURCE_LENGTH, truncation=True,
padding="longest", return_tensors="pt")
input_ids = batch['input_ids']
input_mask = batch['attention_mask']
outputs = trained_model.generate(
input_ids=input_ids, attention_mask=input_mask,
min_length=8,
temperature=1.0, # 生成にランダム性を入れる温度パラメータ
num_beams=5, # ビームサーチの探索幅
diversity_penalty=1.0, # 生成結果の多様性を生み出すためのペナルティ
num_beam_groups=5, # ビームサーチのグループ数
num_return_sequences=3, # 生成する文の数
repetition_penalty=1.5, # 同じ文の繰り返し(モード崩壊)へのペナルティ
)
# 生成されたトークン列を文字列に変換する
generated_titles = [tokenizer.decode(ids, skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for ids in outputs]
return {
"statusCode": 200,
"body": json.dumps({"generated_titles": generated_titles}),
}
Local 環境でのテスト
まず、sam buildでビルドしたのち、sam local start-apiコマンドを実行して、ローカル環境でサーバを起動させます。
次に、postmanを利用して、動作を確認します。
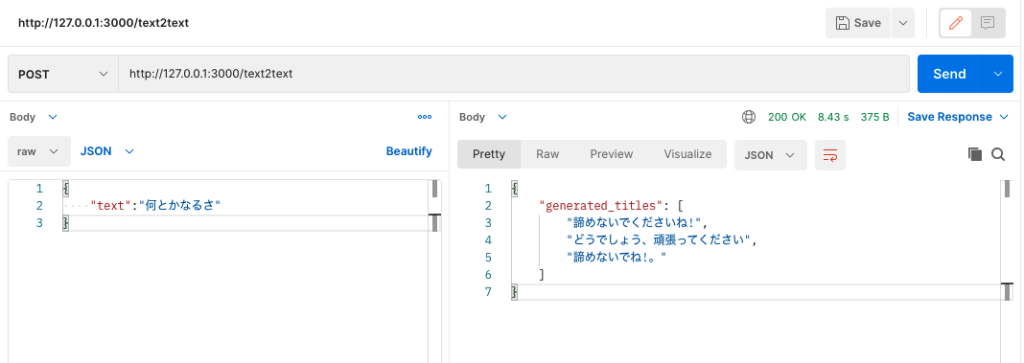
想定通りの応答を返してくれているようです。
Lamdaへのデプロイ
sam deploy --guided コマンドで、Lambdaにデプロイします。
Stack Name [text2text]:
AWS Region [ap-northeast-1]:
#Shows you resources changes to be deployed and require a 'Y' to initiate deploy
Confirm changes before deploy [Y/n]:
#SAM needs permission to be able to create roles to connect to the resources in your template
Allow SAM CLI IAM role creation [Y/n]:
#Preserves the state of previously provisioned resources when an operation fails
Disable rollback [y/N]:
HelloWorldFunction may not have authorization defined, Is this okay? [y/N]: y
Save arguments to configuration file [Y/n]:
SAM configuration file [samconfig.toml]:
SAM configuration environment [default]: 以上でデプロイは完了です。
(おまけ) Lambda のコスト見積もり
今後、この形式でサーバレス推論を実装していくにあたり、コストがどのくらいかかるのか、見積もっておきたいと思います。
見積り条件
- アーキテクチャ x86
- リクエスト数 : 10万件/月
- 割り当てメモリ量 : 3000MB
- エフェメラルストレージの量:1024MB
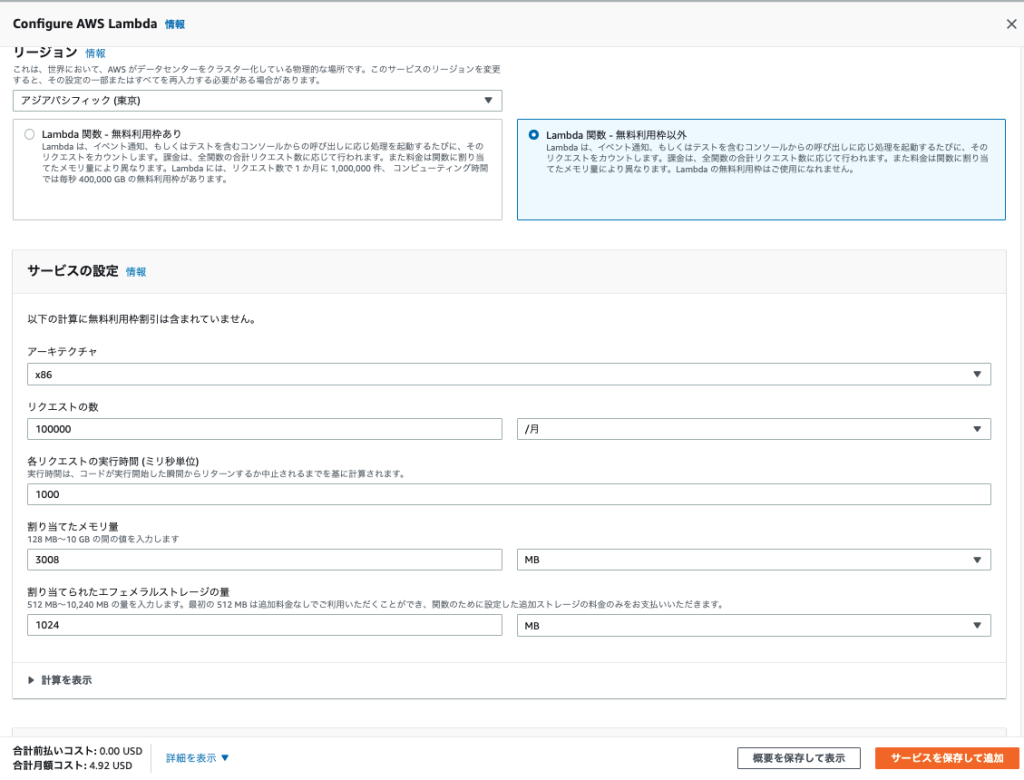
計算結果
単位変換
- 割り当てたメモリ量: 3008 MB x 0.0009765625 GB (MB 単位) = 2.9375 GB
- 割り当てられたエフェメラルストレージの量: 1024 MB x 0.0009765625 GB (MB 単位) = 1 GB
料金の計算
- 100,000 リクエスト x 1,000 ミリ秒 x 0.001 ミリ秒から秒への変換係数 = 100,000.00 合計コンピューティング (秒)
- 2.9375 GB x 100,000.00 秒 = 293,750.00 合計コンピューティング (GB-s)
- 293,750.00 GB-s x 0.0000166667 USD = 4.90 USD (1 か月のコンピューティング料金)
- 100,000 リクエスト x 0.0000002 USD = 0.02 USD (1 か月のリクエスト料金)
- 1 GB - 0.5 GB (追加料金なし) = 0.50 関数あたりの GB 請求可能エフェメラルストレージ
- 0.50 GB x 100,000.00 秒 = 50,000.00 合計ストレージ (GB-秒)
- 50,000.00 GB-s x 0.000000037 USD = 0.0019 USD (エフェメラルストレージの月額料金)
- 4.90 USD + 0.02 USD + 0.0019 USD = 4.92 USD
計算結果は、 無料利用枠をご利用されない場合 (毎月): 4.92 USD と、なりました。(Lambdaのみ)

