自然言語処理モデルを直感的に理解したい(1) Transformer
「ChatGPTはなぜ自然な会話ができる様になったのか?」 多くの人が不思議に思うことだと思います。私はAIの研究者ではなくシステム開発者なので、元となる自然言語処理モデルを自分で作ったり、評価したりすることはないと思います。
それでもどのような仕組みなのかは理解したいと思い、自分なりに整理をしてみました。
AIモデルとコンピュータプログラム
自然言語処理モデルとは何なのかを理解する前に、汎用的な「AIのモデル」について、「従来のプログラム」と何が違うのかをざっくりと理解します。ここでいうAIモデルとは、深層学習(Deep Learning)以降のモデルを指しています。
プログラムを説明する場合には、プロセス(処理)という言葉をよく使います。一本のプログラムは、「データを入力」すると、「手順に従って状態を変化させながら」「データを出力する」します。この「手順に従って状態を変化させながら」の部分を「プロセス」と呼んでいます。
「プロセス」は”記憶”と、”演算””と、”条件分岐”の塊であるといっても良いかと思います。
AIにおいて、この「プロセス」にあたるものが「モデル」だと考えます。「モデル」はあるアーキテクチャ(構造)を持った演算と多くのパラメータの塊です。アーキテクチャは人工知能の教科書によく載っているCNNやRNN、自然言語処理の世界で主流のTransformerなどがそれにあたります。
モデルは「学習」といった過程を経ることで、パラメータが変化します。 学習後のモデルは、ある入力に対して、目標とする出力に近い結果を得ることができます。同じモデルでも学習させるデータによっては結果が変わることとなります。
直感的には学習させるデータが多いほど、目標とする出力に近づくことが期待できます。これは、平面上のグラフでデータをプロットしながら、それらのデータを表現する近似式を作っていく方法に似ています。プロットするデータが学習データ、近似式がモデルです。
最初から近似式がわかっているのであれば、従来のプログラムで正しい答えを出すことができるのですが、データしかない場合は、近似式の形(例えば指数関数とか、対数関数など)を推定して、データを当てはめていき、一番近い係数(=パラメータ)を求めて近似式を決定することが必要になります。
この様に平面上にプロットする問題ではx、yの2種類のデータしか存在しない(=2次元ベクトルで表現できる)ので、ある程度人間でも推定できます。
しかしながら、実世界では多様なデータが複雑に関連して存在します。
例えば自然言語処理の場合、単語(トークン)を一つの単語ベクトルを使って表現しますが、その次元数はBERT -Baseにおいては768次元となっています。これが、GPT-3になると12,288次元にもなるそうです。この様な多次元ベクトルを使うことによって、単語間の関係や、文章の構造を表すことができます。
自然言語処理のように、従来プログラムでは条件分岐を上手く定義できない問題でも、AIは学習をさせることによって、大量のパラメータを決定し、答えを推定することができるということです。
自然言語処理モデル
自然言語処理自体は数十年も前から様々なアプローチがなされてきましたが、ここでは近年の技術について調べていきたいと思います。
自然言語処理(NLP)とは人間が使う言語を入力として、様々なタスクを行う技術です。具体的には、”分類”、”文書生成”、”翻訳”などがタスクにあたります。
自然言語処理モデル(NLPモデル)は、タスクによって基本的なアーキテクチャが異なりますが、最近のモデルはTransformerをベースとしているものが多いようです。有名なモデルとしてはGoogleが開発したBERT(Bidirectional Encoder Representations from Transformers)があります。BERTは2018年の発表当時、様々なタスクにおいて圧倒的な性能を示し、その後に多くの改良版へと発展していきます。
Chat GPTのモデルであるGPT(Generative Pre-trained Transformer)も、Transformerをベースとしたモデルとなっています。
今流行りの自然言語処理モデルを理解するためには、Transformerアーキテクチャを理解する必要がありそうです。
Transformerアーキテクチャ
自然言語処理で扱うデータは時系列データです。このようなデータを扱う場合には、RNN (Recurrent Neural Network)がよく使われていました。 「回帰型ニューラルネットワーク」という名前が示すとおり、内部に循環構造を持っており、最初のデータ処理の結果が後続のデータ処理の入力になります。
しかし、RNNにはいくつかの問題がありました。並列処理ができず処理時間がかかること、長期的な依存関係を捉えることが難しい事といった問題です。このためRNNにもいくつかの改良版が開発されましたが、TransformerはRNNの改良版とは別のアプローチでこれらの問題を解決し、自然言語処理モデルで多く使われることとなりました。
Transformerの最大の特徴は、セルフアテンションメカニズム(Self-Attention Mechanism)を導入している点です。セルフアテンションメカニズムにより、入力された文章中の単語間の関係性を捉えることができ、文脈の理解が格段に向上します。
2017年に発表された有名な論文「Attention Is All You Need(リンク)」において、Transformerが発表されました。この論文の図1を以下に引用します。
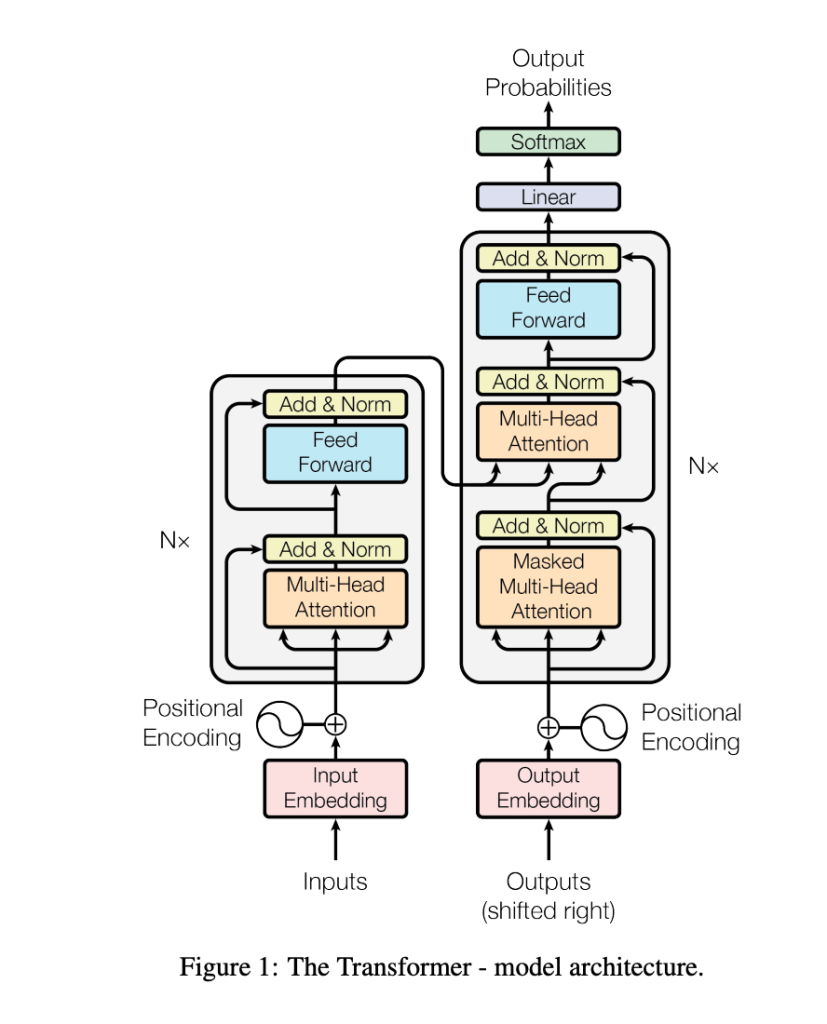
この図の構成要素を簡単に説明すると以下の様になります。
- 入力エンベディング層:入力テキストをトークン化し、埋め込みベクトルに(数値に)変換します。
- 位置エンコーディング:各トークンに位置情報を加えて、単語の順序を考慮します。
- エンコーダ層:図の左側のグレー部分です。入力シーケンスを抽象表現に変換します。N× はこの層がN個あることを示しています。
- デコーダ層:図の右側のグレー部分です。エンコーダからの情報を利用してターゲットシーケンスを生成します。N× はこの層がN個あることを示しています。
- 出力層:線形層とソフトマックス関数を使って、デコーダの出力をタスク固有の形式(例えば、単語の確率分布)に変換します。
この構造の中で、最も重要なマルチヘッドアテンション(Multu-Head Attention)について調べていきます。
Multi-Head Attention
Transformer以前にもアテンション機構は存在しました。先述の論文のタイトルは「Attention Is All You Need」でした。つまりAttentionの意味がわかればTransformerアーキテクチャの基本概念が理解できると思います。
アテンションは、シーケンス間の対応関係を計算するための機構で、特にSeq2Seqモデル(翻訳などの文章を入力して、文章を出力するモデル)で広く使用されています。アテンションは、入力シーケンス内の各要素に対して、出力シーケンスの各要素がどれだけ注意を払うべきかを計算します。これにより、モデルは長期依存関係を効果的に捉えることができます。
先の論文から図2を引用します。
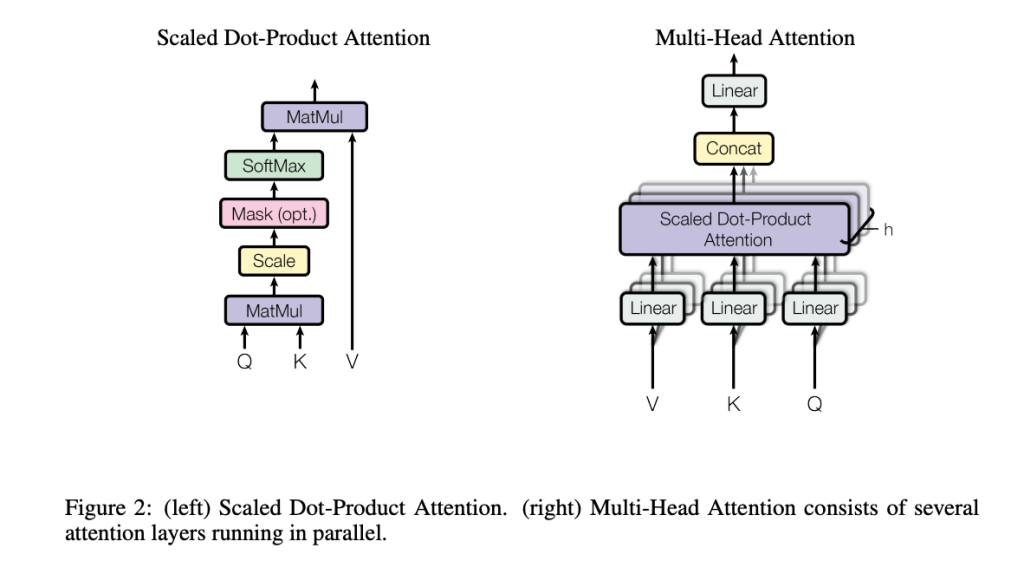
図2の右側はMulti-Head Attentionの構造を表しています。Multi-Head AttentionはScaled Dot-Product Attentionを束ねた構造をしています。
そこで、今度は左側のScaled Dot-Product Attentionに着目します。
この方法では、クエリ(Query)、キー(Key)、バリュー(Value)の3つのベクトルが扱われます。Scaled Dot-Product Attentionは以下の手順で計算されます。
- スコアの計算: クエリ(Query)ベクトルとキー(Key)ベクトルの内積を計算します。これにより、各トークンが他のすべてのトークンとどの程度関連しているかを示すスコアが得られます。
- スケーリング: スコアを、キー(Key)ベクトルの次元数(通常はd_k)の平方根で割ります。これにより、内積の値が大きくなりすぎることを防ぎ、勾配の問題を緩和します。
- スコアの正規化: スコアを正規化するために、softmax関数を適用します。softmax関数により、スコアが0から1の範囲になり、合計が1になるようになります。これにより、各トークンが他のトークンにどの程度の重みを与えるかが決定されます。
- 重み付けされたバリューの計算: 正規化されたスコアを使用して、各トークンのバリュー(Value)ベクトルに重み付けを行います。これにより、各トークンが他のトークンからどの程度情報を受け取るかが決定されます。
Multi-Head Attentionは、これらのAttentionの結果を結合し、一つの大きなコンテキストベクトルを生成します。
スコアの計算
ここで、スコアの計算について、さらに噛み砕いていきたいと思います。
入力された文章は、事前にトークンに分解され、それぞれベクトル化されています。\(i\)番目のトークンのベクトルを\(\boldsymbol x_i\)とします。
各トークンに対して、クエリ(\(\boldsymbol q\))、キー(\(\boldsymbol k\))、バリュー(\(\boldsymbol v\))のベクトルを生成します。
\(i\)番目のトークンに対するそれぞれのベクトルは、(\(\boldsymbol q_i\)),(\(\boldsymbol k_i\)),(\(\boldsymbol v_i\))とします。
それぞれのベクトルの役割は、以下のとおりです。
Query: クエリベクトルは、他のトークンに対する関心度や関連性を表現する役割を持ちます。
Key: キーベクトルは、他のトークンが参照する際の「アンカーポイント」のような役割を果たします。
Value: バリューベクトルは、トークンの実際の情報や内容を保持します。
Scaled Dot-Product Attentionでは、ベクトルの内積が2つのベクトルの関連度を表すことを使って、スコアを以下の様に計算します。
$$ {\hat{a}}_{ij} = \frac {\boldsymbol q_i \cdot \boldsymbol k_j}{\sqrt{d}}$$
ここで\(d\)は、ベクトルの次元です。
あらためて、RNNの問題点を思い出してみます。RNNの場合にはステップを経るごとに前のトークンの情報が失われていきました。しかし、この計算のようにあるトークンのスコア値を決定する際に、すべてのトークンの情報を直接使ってスコアを計算することができ、離れたトークンの情報も考慮することが可能となります。またすべてのトークンに対する計算を並列に行うことが可能なため、処理の高速化も図れます。
事前学習
最後の疑問はクエリ、キー、バリューってどうやって生成するの?ということです。
Transformerを使ったモデルは、大量のテキストデータを使って事前学習をします。事前学習では、単語やトークンの埋め込み表現(単語埋め込みベクトル)と、モデルのパラメータ(重みとバイアス)を計算します。
重み行列は、\({W_Q, W_K, W_V} \)、バイアス項は\(b_Q、b_K、b_V\)です。
事前学習により、モデルは言語の文法や構造、文脈、単語間の関連性などの知識を獲得し、それらの情報がモデルのパラメータに反映されます。
この重み行列と、バイアス項とを使ってクエリー、キー、バリューは以下の様に計算されます。
$$Q = W_Q * input\_embedding + b_Q $$
$$K = W_K * input\_embedding + b_K $$
$$V = W_V * input\_embedding + b_V$$
ChatGPTによるクエリ、キー、バリューの説明
以降、ChatGPT(GPT-4)に具体的な例を使って説明してもらいました。
まずは、これらの値を概念的に理解できるように説明してもらいます。
例として、「犬は庭でボールを追いかけている」という文を考えてみましょう。
- クエリ(q): クエリは、文中の特定の単語(例:「追いかけて」)が他の単語(例:「犬」、「庭」、「ボール」)とどのように関連しているかを質問します。この場合、「追いかけて」が他の単語とどのように関連しているかを理解しようとします。
- キー(k): キーは、各単語がクエリ(「追いかけて」)とどのように関連しているかを表すインデックスの役割を果たします。例えば、「犬」のキーは、「追いかけて」との関連性を示すもので、「庭」や「ボール」といった他の単語も同様にキーを持ちます。
- バリュー(v): バリューは、各単語の情報を表すコンテンツです。クエリとキーによって、それぞれの単語がどれだけ関連しているかが計算された後、関連性が高い単語のバリュー(情報)が選択されます。例えば、「追いかけて」というクエリに対して、「犬」と「ボール」がより関連性が高いと判断された場合、これらの単語のバリューが重要な情報として抽出されます。
この具体例を通じて、クエリ、キー、バリューの概念がどのように文中の単語間の関連性を捉えるために使用されるかを理解できるでしょう。Self-Attention Mechanismは、このプロセスを通じて、各単語に対する文脈情報を提供し、言語表現を改善します。
次に、これらの値の事前学習の過程を概念的に理解できるように説明してもらいます。
事前学習の過程では、モデルは大量のテキストデータを用いて学習し、言語表現を獲得します。この過程で、モデルは特定のタスクには特化していませんが、一般的な言語理解能力を身につけることが目的です。具体的な例を使って、事前学習の過程でどのように学習されるか説明しましょう。
例として、以下のような文章を考えてみましょう。
- 猫はベッドで寝ている。
- 子供たちは公園で遊んでいる。
- サッカー選手はボールを蹴っている。
事前学習の過程では、モデルはこれらの文章から、単語間の関係や一般的な文法規則を学習します。この過程で、クエリ(q)、キー(k)、バリュー(v)の重み行列が調整され、最適化されます。
具体的には、モデルは以下のような学習を行います。
- ある単語(クエリ)が他の単語(キー)とどのように関連しているかを学習します。例えば、「寝ている」という単語が「猫」や「ベッド」と関連していることを学習します。
- 類似の文脈で使われる単語に対して、似たようなクエリ、キー、バリューのベクトルが生成されるように学習します。例えば、「寝ている」、「遊んでいる」、「蹴っている」は、それぞれ似たような文法構造を持つ動詞であるため、これらの単語に対応するベクトルは互いに似たような特徴を持つことが期待されます。
- 文脈に基づいて単語の意味が適切に捉えられるように、バリューベクトルが最適化されます。例えば、「公園で遊んでいる」の文脈では、「遊んでいる」のバリューが「子供たち」と関連性が高く、「サッカー選手」とは関連性が低いことが学習されます。
これらの学習過程を経て、モデルは最適なクエリ、キー、バリューの重み行列を獲得し、事前学習が完了します。この段階で得られたモデルは、一般的な言語理解能力を持っていますが、特定のタスクにはまだ適用できません。
次のステップであるファインチューニングでは、モデルは特定のタスクに対して最適化されます。例えば、質問応答や感情分析などのタスクにおいて、モデルはそのタスクに特化した知識を学習します。
要約すると、事前学習の過程では、モデルは大量のテキストデータを用いてクエリ、キー、バリューの重み行列を学習し、一般的な言語理解能力を獲得します。その後、ファインチューニングを行うことで、モデルは特定のタスクに対して最適化され、より高い性能を発揮することができます。
今回はTransformerがなぜ使われているのかを調べるために、アテンションについて掘り下げてみました。次回はいくつかのモデルについて、違いを見ていきたいと思います。

