応答生成モデルの実装
構成の選択
一番最初の記事に記載した通り、iOSのアプリケーションから「発話」をテキストで送信すれば「応答」をテキストで返す様にしたいと思います。
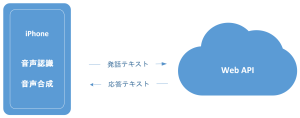
このwebAPIを実装する方法として、大きく2種類あります。
1つは、HuggingFace社の推論APIを利用する方法、もう一つは自前でサーバを立てる方法法です。自前でサーバ(VPS)を立てる場合には、さらに、”どこにサーバを置くか”という、選択も考えなければなりません。
まずは、この辺を整理しておきます。
| メリット | デメリット | |
| HuggingFace API | サーバの管理が不要 パフォーマンスが良い GPUも使える | 無料の場合は起動時に数十秒待たされる。Pin modelにしておけば即応可能になる。 ($1/day on CPU, $5/day on GPU) 一定量以上の文字数をリクエストで送ると有料になる。 (Text input tasks: $10/M characters on CPU, $50/M characters on GPU |
| 自前サーバ(VPS) | 比較的に低価格で実現可能 | サーバの管理が面倒 パフォーマンスが悪い(応答に2倍程度の時間がかかる) GPUが使えない、スケーラブルに拡張できないので、ユーザが増えると不安 |
結局のところ、コストと性能のトレードオフになりますが、今回は実験的なサーバなので、VPSを選択します。いくつかのVPSを比較検討した結果、一番安価ものを選択しました。ちなみに選択したVPSは時間単位の課金となっていました。1時間あたりでは税込2.2円になりますので、実験的に試してみたい場合は、終わった時に削除してしまえば、さほどコストはかかりません。
HuggingFaceへのモデル登録
以下、VPSを使った実装の説明をしていきますが、モデルの管理のために、HuggingFaceへ学習済みモデルの登録をしておきます。
HuggingFace社のページでアカウントを作成します。アカウントの作成は無料です。
次にサイドバーのメニューから 「New - Model」を選択して新しいモデルを作成します。
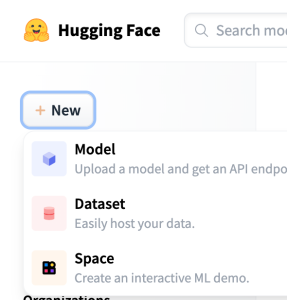
モデル作成時にpublicとprivateが選択できますが、privateの場合には、APIを実行する際に、APIキーが必要となります。こちらは後でpublicに変更することもできますので、最初はprivateにしておいたら良いかと思います。最後にFiles and versions で、作成したモデルのファイルをアップロードすれば準備はOKです。
Model card画面にある Hosted inference APIを使って、試してみます。
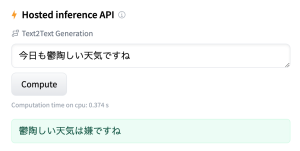
[Your sentence here..]にテキストを入力してComputeボタンを押すと、応答テキストが返ってきました。
最後に右上のアカウントアイコンからsettingsを選択して、Access Tolkensを取得しておきます。
VPSの立ち上げ
VPSもいろんな企業が提供しておられますが、私は現時点で最安値のWeb ARENA IndigoTMを選択しました。
CPU,メモリなどの違いで7段階のプランがあります。低価格のプランから順番に試してみましたが、4vCPU、4GBメモリのプランでギリギリ動きました。
開発環境は、VSCodeにRemote-SSHのプラグインを入れて、直接コード編集できるようにしました。
.sshフォルダのconfigファイルはこんな感じ
Host <ホスト名>
HostName <IPアドレス>
User ubuntu
IdentityFile ~/.ssh/secret_key/private_key.txt
port 22
TCPKeepAlive yes
ServerAliveInterval 60
IdentitiesOnly yesこれで、VSCodeのリモートエクスプローラーから<ホスト名>を指定して、ファイルの編集ができます。また、ターミナルからは、ssh <ホスト名>でログインできる様になります。
推論API ソースコード
推論APIは、flask+gunicornのフレームワークで動作させています。
必要なライブラリは、requirements.txtで定義しています。
flask
gunicorn
transformers
sentencepiece
torchアプリ本体のソースコードです。
ソースコードと同じフォルダに"model"フォルダを作り、その下に学習ずみの応答生成モデルを置いています。
from flask import Flask,request,jsonify,abort
from transformers import T5ForConditionalGeneration, T5Tokenizer
tokenizer = T5Tokenizer.from_pretrained("./model")
trained_model = T5ForConditionalGeneration.from_pretrained("./model")
app = Flask(__name__)
app.config['JSON_AS_ASCII'] = False
@app.route('/t2t',methods=['POST'])
def t2t():
try:
json = request.get_json()
data = json['inputs']
MAX_SOURCE_LENGTH = 24 # 入力される記事本文の最大トークン数
MAX_TARGET_LENGTH = 24 # 生成されるタイトルの最大トークン数
# 推論モード設定
trained_model.eval()
# 前処理とトークナイズを行う
inputs = [data]
batch = tokenizer.batch_encode_plus(
inputs, max_length=MAX_SOURCE_LENGTH, truncation=True,
padding="longest", return_tensors="pt")
input_ids = batch['input_ids']
input_mask = batch['attention_mask']
# 生成処理を行う
outputs = trained_model.generate(
input_ids=input_ids, attention_mask=input_mask,
min_length=8,
temperature=1.0, # 生成にランダム性を入れる温度パラメータ
num_beams=5, # ビームサーチの探索幅
diversity_penalty=1.0, # 生成結果の多様性を生み出すためのペナルティ
num_beam_groups=5, # ビームサーチのグループ数
num_return_sequences=3, # 生成する文の数
repetition_penalty=1.5, # 同じ文の繰り返し(モード崩壊)へのペナルティ
)
# 生成されたトークン列を文字列に変換する
generated_words = [tokenizer.decode(ids, skip_special_tokens=True,
clean_up_tokenization_spaces=False)
for ids in outputs]
return jsonify(generated_words)
except Exception as e:
return (e)
if __name__ == '__main__':
app.run(host='0.0.0.0', port=8081)
生成処理のコア部分は、GoogleColabのコードをそのまま持ってきています。あとは、入出力のための前処理と後処理を加えているだけです。
これで、応答生成サーバができました。http://<ホスト名>/t2t に発話テキスト{'inputs':'発話テキスト'}をポストしてあげると、num_return_sequences個(ここでは3個)の候補文を返してきます。
応答生成モデルに関しては、これで終了です。
