Hugging FaceのInference Endpointを使って推論サーバを構築する
Transformerの推論モデルを自作のソフトウエアから使う方法は、いくつかの選択肢があります。以前の記事では、AWSのLamdaにモデルをデプロイする方法を紹介しました。
Transformerの学習済みモデルをLambdaにデプロイする(SAM)
前回もTransformerの学習済みモデルをLambdaにデプロイしましたが、別の方法を試してみます。 今回は、AWS Serverless Application Model(sam)を使っています。 同じ目的…

昨日、Hugging Faceからメールが届き、新しくInference Endpointというサービスを開始したということなので、早速、試してみたいと思います。

Inference Endpointの構築
Inference Endpointの利用には、Payment information(クレジットカード情報)の登録が必要になります。利用する場合には、Edit profileからbillingをクリックして登録できます。
アカウントの登録が完了したら、こちらのページから、[Deploy your first model]をクリックします。
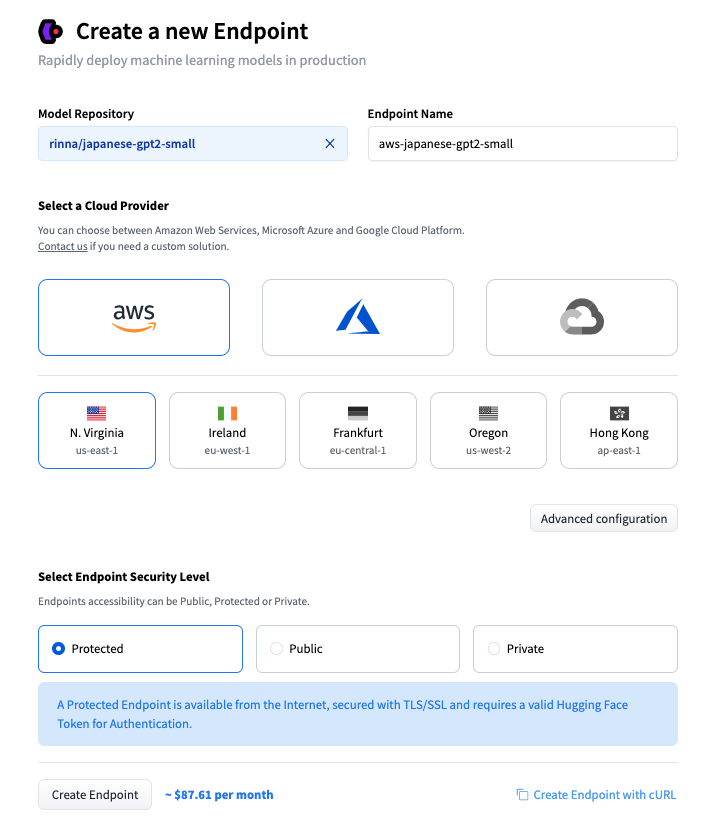
Model Repositoryに、利用するモデルを入力します。privateモデルは使えない様です。
Select a Cloud Providerで、利用するプロバイダを選択します。現時点(2022年10月13日)ではGoogle cloudは選択できません。Azureは選択はできますが、うまくビルドすることができませんでした。特にこだわりがなければAWSで良いかと思います。AWSのアカウントがなくても利用できます。
Select Endpoint Security Level で、Protectedを選択すると、Tokenによる認証が必要になります。通常の利用ではこれで問題ないかと思います。Privateを選択すると、インターネットからの利用ができなくなります。企業内利用などの場合でセキュリティを高めたい場合には、こちらを選択しますが、AWSのアカウントIDの入力が求められます。
基本的には、以上の3箇所の入力だけで Endpointができてしまいます。
Advanced configurationをクリックすると、以下のような設定が可能となります。ちなみに、Instance typeと、Replica autoscalingは、後で、Updateすることもできる様です。
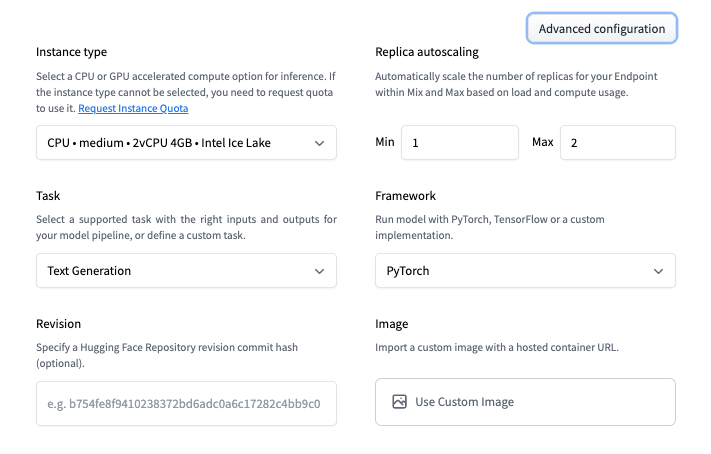
設定は、本当に数秒で完了します。buildも数分で完了したかと思います。
Inference Endpointの利用
今回は ”rinna/japanese-gpt2-small”を使ってEndpointを作成しています。このモデルは、Text Generationモデルで、入力した文字列に続く文章を生成してくれます。
それでは、実際に使えるかどうか、Google Colaboratoryで試してみます。
import json
import requests
API_URL= <Inference Endpointの URL>
access_token =<HuggingFaceのアカウントのAPI Token>
headers = {"Authorization": f"Bearer {access_token}",
"Content-Type": "application/json"}
def query(payload):
data = json.dumps(payload)
response = requests.request("POST", API_URL, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))input= {"inputs":"トンネルを抜けると、"}
query(input)
- 実行結果
[{'generated_text': 'トンネルを抜けると、道なりに左カーブし、坂下の林道を下っていく。 そのままカーブを左に曲がり、2つ目の細い道を抜けると左側に日赤の研修所入口の看板がある。 日赤'}]
うまく実行できた様です。
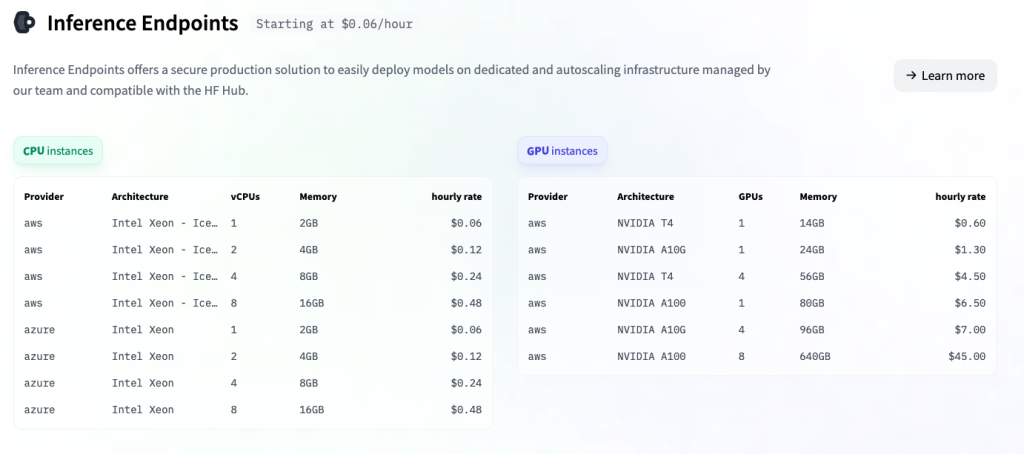
おまけ)コストについて
Inference Endpointsのコストは、利用するCPU/GPUやautoscalingの設定によって変わってきます。最小構成では、$0.06/hour(GPUの場合は$0.6/hour)ですから、$1.44/dayとなります。以前のInference APIでは$1/day(GPUの場合は$5/day)でピン留めできましたので、使い方によっては、少し高くなってしまっているかもしれません。
しかしながら、このお手軽さは大変魅力的です。例えば、GPUで実験したい場合などは、今までは日単位の課金だったのが、分単位になるということで、個人ユーザにとっても利用価値があるものと考えます。