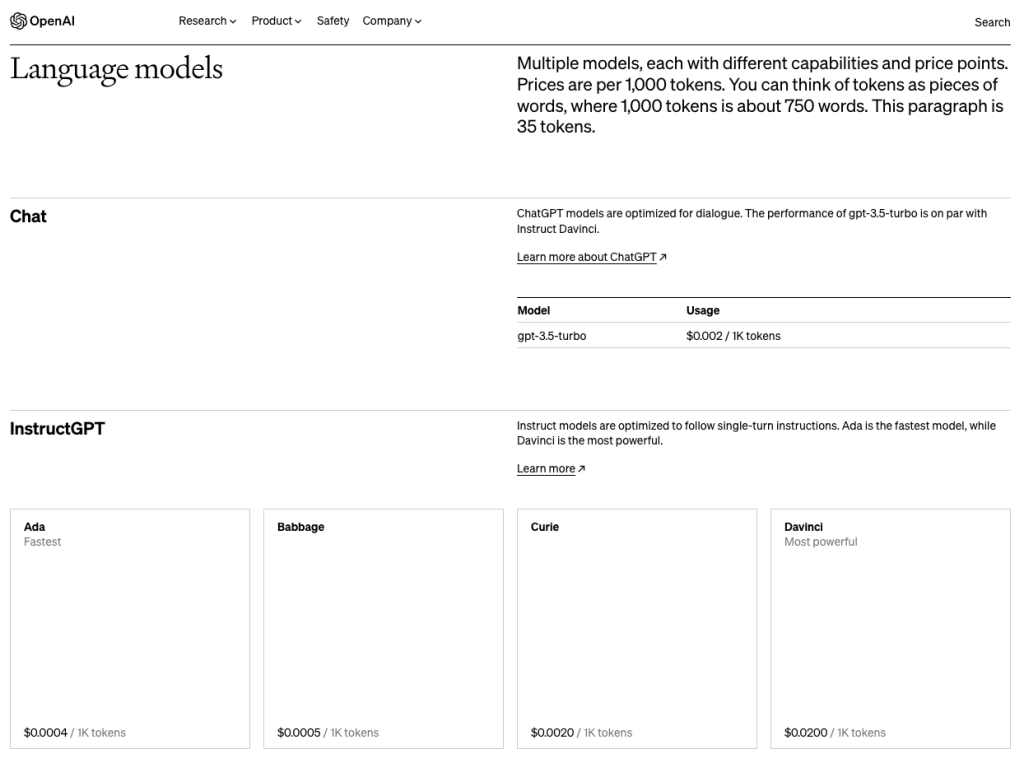
Most capable GPT-3.5 model and optimized for chat at 1/10th the cost of text-davinci-003. Will be updated with our latest model iteration.
4,096 tokens
Up to Sep 2021
gpt-3.5-turbo-0301
Snapshot of gpt-3.5-turbo from March 1st 2023. Unlike gpt-3.5-turbo, this model will not receive updates, and will only be supported for a three month period ending on June 1st 2023.
4,096 tokens
Up to Sep 2021
text-davinci-003
Can do any language task with better quality, longer output, and consistent instruction-following than the curie, babbage, or ada models. Also supports inserting completions within text.
4,000 tokens
Up to Jun 2021
text-davinci-002
Similar capabilities to text-davinci-003 but trained with supervised fine-tuning instead of reinforcement learning
import requests
import json
# Note: you need to be using OpenAI Python v0.27.0 for the code below to work
import openai
response=openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "日本人選手で一番人気があるのは誰?"}
]
)
print(response['choices'][0]['message']['content'])
The main input is the messages parameter. Messages must be an array of message objects, where each object has a role (either “system”, “user”, or “assistant”) and content (the content of the message). Conversations can be as short as 1 message or fill many pages.
Typically, a conversation is formatted with a system message first, followed by alternating user and assistant messages.
The user messages help instruct the assistant. They can be generated by the end users of an application, or set by a developer as an instruction.
The system message helps set the behavior of the assistant. In the example above, the assistant was instructed with “You are a helpful assistant.”
The assistant messages help store prior responses. They can also be written by a developer to help give examples of desired behavior.
Including the conversation history helps when user instructions refer to prior messages. In the example above, the user’s final question of “Where was it played?” only makes sense in the context of the prior messages about the World Series of 2020. Because the models have no memory of past requests, all relevant information must be supplied via the conversation. If a conversation cannot fit within the model’s token limit, it will need to be shortened in some way.
The value of the Access-Control-Allow-Origin to send in the response. Keep in mind that even though the Access-Control-Allow-Origin header can be set to a string that is a space separated list of origins, this behavior does not work on all clients that implement CORS. You should only supply a single origin to the CORSConfig object. If you need to supply multiple origins you will need to define a custom handler for it that accepts OPTIONS requests and matches the Origin header against a whitelist of origins. If the match is successful then return just their Origin back to them in the Access-Control-Allow-Origin header.allow_headers¶
The list of additional allowed headers. This list is added to list of built in allowed headers: Content-Type, X-Amz-Date, Authorization, X-Api-Key, X-Amz-Security-Token.expose_headers¶
A list of values to return for the Access-Control-Expose-Headers:max_age¶
The value for the Access-Control-Max-Ageallow_credentials¶
A boolean value that sets the value of Access-Control-Allow-Credentials.