Transformerの学習済みモデルをLambdaにデプロイする
前回、flask で作ったAPIをChaliceを使ってLambdaにデプロイしてみました。
AWS Lambda のChalice使ってflask APIをデプロイする
前回、Netlifyの記事を書きましたが、今回は、Chaliceです。 接続としては、以下の通りです。 <LINE> ー <Dialogflow> ー <heroku> ー <V […]

この方法は、アプリをzip形式でアップロードします。zip形式は、最大250MBのサイズ制限がありますので、HuggingFaceの学習モデルを使った推論サーバには使えません。
しかし、Lambdaには、zipではなくDockerコンテナを使う方法もあり、こちらだと最大10GBまでのコンテナをデプロイできるようです。
以下のサイトを参考に、Lambdaでサーバレス推論を試してみました。
<サーバーレス推論のためにAWSLambdaでHuggingFaceモデルをホストする>
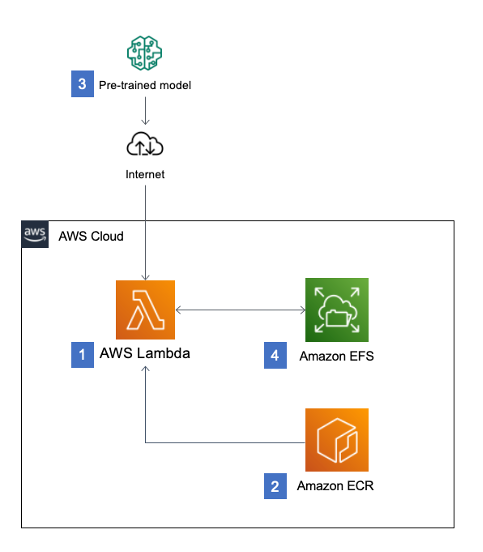
図にありますように、DockerイメージファイルはAmazon ECRに格納されます。また学習済みモデルは、Amazon EFSに配置されます。
上記サイトでは、サンプルプログラムをgit cloneできますので、必要な事前準備を済ませたのち、以下を実行するとサーバレス推論が実行可能となります。
$ git clone https://github.com/aws-samples/zero-administration-inference-with-aws-lambda-for-hugging-face.git
$ cd zero-administration-inference-with-aws-lambda-for-hugging-face
$ pip install -r requirements.txt
$ cdk bootstrap
$ cdk deploy日本語モデルへの変更
上記のままでは、モデルが日本語対応していませんので、結果は思ったようにはなりません。
sentiment-analysisの方を日本語のモデルに変更してみます。今回使用するモデルは、"daigo/bert-base-japanese-sentiment"としました。
変更点は、2点です。
1)inferenceフォルダにあるsentiment.pyを以下のように変更します。
"""
Copyright Amazon.com, Inc. or its affiliates. All Rights Reserved.
SPDX-License-Identifier: MIT-0
"""
import json
from transformers import pipeline
## モデルを明示的に指定
nlp = pipeline("sentiment-analysis",model="daigo/bert-base-japanese-sentiment",tokenizer="daigo/bert-base-japanese-sentiment")
def handler(event, context):
response = {
"statusCode": 200,
"body": nlp(event['text'])[0]
}
return response2) 日本語処理のための fugashi ipadicモジュールを追加
fugashiはMecabのラッパーになります。辞書としてipadicが必要となります。この2つをrequirements.txtに追加してみたのですが、pip installされません。
Dockerfileを見てみると、どうも必要なモジュールを直接インストールしているようです。修正するのも面倒なので、直接上記の2つのモジュールをDockerfileに追記しました。
# Install the function's dependencies
RUN pip uninstall --yes jupyter
RUN pip install --target ${FUNCTION_DIR} awslambdaric
RUN pip install --target ${FUNCTION_DIR} sentencepiece protobuf fugashi ipadic // ここに追記以上で、日本語のポジネガ判定が、サーバレスで推論できるようになりました。
Lambdaのテストタグから、
{
"text": "明日も晴れるといいね"
}を送信してみると、以下のような結果が得られます。
{
"statusCode": 200,
"body": {
"label": "ポジティブ",
"score": 0.9717926979064941
}
}最初の実行時間は、コールドスタートのため、8ー10秒程度かかりますが、連続して実行する場合、2回目以降は0.3〜0.5秒程度で応答があります。
システムから組み込むときには、トリガーを追加して、APIGatewayを指定すれば良いかと思います。
(おまけ)事前準備
まず、python環境とnode環境をきれいにしておくことをお勧めします。私の場合、pythonの勉強段階でよくわけがわからないままに、いろんなパッケージ管理ツールを使っていたために、相当酷い環境になっていました。途中で行き詰まったため、これを機に一旦全ての環境を削除して構築し直しています。また、AWS CDKはnode.jsのnpmを必要とするため、node.jsのインストールも必要です。
その上で、必要なものは以下の4つと記載されています。
- git
- AWS CDK
- Python 3.6以上
- 仮想環境
結果的に動作はしたものの、最後までnpmのグローバルインストールの正しい設定方法がわからず、cdkコマンドは、 ~/.npm-glocal/binへのパスを手動で設定することになりました。
(追記)
この後、以下の記事でも同様のサーバレス推論を試しています。ご参考にしてください。
Transformerの学習済みモデルをLambdaにデプロイする(SAM)
前回もTransformerの学習済みモデルをLambdaにデプロイしましたが、別の方法を試してみます。 今回は、AWS Serverless Application Model(sam)を使っています。 同じ目的…
