Transformerの仕組みを体系的に理解したい 第1章、第2章
Transformerは、生成AIを理解する上で重要な技術です。以前、「直感的に理解したい」と思い、調べた結果を以下の記事にしました。
自然言語処理モデルを直感的に理解したい(1) Transformer
「ChatGPTはなぜ自然な会話ができる様になったのか?」 多くの人が不思議に思うことだと思います。私はAIの研究者ではなくシステム開発者なので、元となる自然言語処理モ…

概念的には理解できたのですが、やはり「体系的に理解したい」と思い、まとめ直してみました。今回は、GPT4oの助けも借りて、自分自身が理解できるようにまとめています。
第1章: Transformerの背景と全体像
1.1 自然言語処理(NLP)における課題とTransformerの登場
自然言語処理(NLP)は、人間の言語をコンピュータで処理する技術です。NLPでは、翻訳、文章生成、分類、要約といったタスクが取り組まれていますが、これらのタスクの基盤には「言語の文脈を理解する能力」が求められます。
従来のアプローチと課題
Transformer以前、自然言語処理には主に以下のモデルが使われていました:
- RNN(Recurrent Neural Network)
- 時系列データを逐次的に処理するモデル。
- 問題点:
- 長期依存関係を捉えるのが困難(勾配消失問題)。
- 並列処理ができず、処理速度が遅い。
- LSTM(Long Short-Term Memory)
- RNNの改良版で、長期依存をある程度捉えられるようにしたモデル。
- 問題点:
- 構造が複雑で計算負荷が高い。
- 長い文脈の処理には依然として限界がある。
Transformerの登場
2017年、Googleの論文「Attention Is All You Need」で提案されたTransformerは、以下の点でこれらの課題を克服しました:
- Self-Attention機構を利用して、単語間の関係を効率的に計算。
- 時系列処理を行わず、並列処理を可能に。
- 長期依存関係を正確に捉える。
1.2 Transformerの基本構造とメリット
Transformerは大きく分けて以下の2つの部分で構成されています:
- エンコーダー(Encoder)
- 入力文を抽象的な特徴ベクトルに変換する部分。
- 複数の層で構成され、各層がSelf-Attentionとフィードフォワードネットワークを持つ。
- デコーダー(Decoder)
- エンコーダーの出力を利用して新しい文を生成する部分。
- エンコーダーから得た情報と、デコーダー自身が生成したトークンを組み合わせて次のトークンを予測する。
Transformerのメリット
- 並列処理が可能
- 時系列依存がないため、GPUの計算能力を最大限活用可能。
- 長期依存関係のモデル化
- Attention機構により、文中のどの単語も一様に関連付け可能。
- 汎用性
- 翻訳、要約、文章生成など、さまざまなタスクに適用可能。
第2章: 単語のベクトル表現と位置エンコーディング
Transformerでは、入力された文章を「数値(ベクトル)」として処理します。この章では、単語のベクトル表現(Word Embedding)と、Transformerの重要な特徴である位置エンコーディングについて詳しく説明します。
2.1 単語埋め込み(Word Embedding)の詳細
Transformerでは、まず文章を単語(トークン)に分割し、各単語をベクトルとして表現します。このベクトルは、単語間の意味的な関係を捉えるように設計されています。
ベクトル空間での単語の意味表現
単語は高次元のベクトル空間内の点として表現されます。この空間では、意味が似ている単語同士が近い位置に配置されます。
例:
- 「猫」→
[0.8, 0.6, -0.4, ...] - 「犬」→
[0.9, 0.5, -0.3, ...] - 「車」→
[-0.2, 0.7, 0.3, ...]
このように、単語間の類似性はベクトル間の距離(例えばユークリッド距離やコサイン類似度)として数値化されます。
具体的には、それぞれのベクトルの内積を計算し、1に近いほど、類似度が高いということができます。
埋め込み層(Embedding Layer)
埋め込み層(Embedding Layer)は、Transformerなどのディープラーニングモデルにおいて、離散的な単語(トークン)を連続的な数値ベクトルに変換するための層です。この層の役割をさらに詳細に説明します。
1. 埋め込み層の目的
- テキストデータは通常、単語やトークンの形で表現されますが、これらはモデルには直接入力できません。そのため、これらを数値ベクトルに変換する必要があります。
- 埋め込み層は、各単語やトークンを連続値ベクトル(埋め込みベクトル)に変換し、モデルが文脈や意味を学習しやすい形にします。
2. 埋め込み層の仕組み
(a) 単語のID化
- モデルに入力する文をトークン化します。トークン化とは、文を単語やサブワードに分割し、それぞれにユニークなIDを割り当てるプロセスです。
- 例えば、文「私は犬が好き」をトークン化すると
[10, 23, 5, 89]のように数値化されます。
(b) 埋め込み行列(Embedding Matrix)
埋め込み層は、学習可能な行列 \(E\)で表現されます。この行列は次のように構造化されています:
\[E \in \mathbb{R}^{V \times d}\]
- \(V\):単語の語彙サイズ(全トークン数)。
- \(d\):埋め込みベクトルの次元数。
行列 \(E\) の各行は、語彙内の各トークンに対応する埋め込みベクトルを持っています。
(c) IDを埋め込みベクトルに変換
- トークンのIDをインデックスとして埋め込み行列 \(E\) にアクセスし、対応する行(埋め込みベクトル)を取得します。
例えば、以下の埋め込み行列 \(E\) があるとします:
\[\text{Embedding} = \begin{bmatrix} 0.1 & 0.2 & \dots & 0.8 \\ 0.3 & 0.5 & \dots & 0.2 \\ \vdots & \vdots & \ddots & \vdots \\ 0.4 & 0.7 & \dots & 0.1 \end{bmatrix}\]
トークン [10, 23, 5, 89] を埋め込み層に通すと、それぞれのIDに対応する行が取得されます。そして、以下のような埋め込みベクトルが得られます:
\[\text{Embedding Output} = \begin{bmatrix} \text{ベクトル for トークン 10} \\ \text{ベクトル for トークン 23} \\ \text{ベクトル for トークン 5} \\ \text{ベクトル for トークン 89} \end{bmatrix}\]
これにより、トークン列 [10, 23, 5, 89] が次元数 \(d\) の連続値ベクトルの列に変換されます。
2.2 位置エンコーディング(Positional Encoding)
Transformerは時系列処理を行わないため、単語の順序情報を直接的には扱えません。そのため、位置エンコーディングを導入し、単語の順序をモデルに伝えます。
位置エンコーディングの数式
位置エンコーディングは、以下の式で計算されます:
\[PE(pos, 2i) = \sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE(pos, 2i+1) = \cos\left(\frac{pos}{10000^{2i/d}}\right)\]
- \(pos\):単語の位置(整数)。
- \(i\):埋め込みベクトル内の次元インデックス。
- \(d\):埋め込みベクトルの次元数。
直感的な解釈
- サイン波とコサイン波
サイン波とコサイン波の周期性により、単語間の相対的な位置関係をモデルが学習できます。 - 次元ごとの異なる周期
高い次元では長期的な位置関係を捉え、低い次元では短期的な関係を捉えます。
具体例
次元数 \(d=4\) 、単語位置 \(pos=0,1,2\)の場合:
| 単語位置 pospospos | 次元1 (sin) | 次元2 (cos) | 次元3 (sin) | 次元4 (cos) |
|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 1 |
| 1 | \(sin(1/10000^0)\) | \(cos(1/10000^0)\) | \(sin(1/10000^{1/2})\) | \(cos(1/10000^{1/2})\) |
| 2 | \(sin(2/10000^0)\) | \(cos(2/10000^0)\) | \(sin(2/10000^{1/2})\) | \(cos(2/10000^{1/2})\) |
補足)
言い換えると、位置エンコーディングとは、位置情報をトークンの特徴量に統合するための仕組みです。これにより、整数値であるposを絶対位置を表すベクトルとして表すことができます。
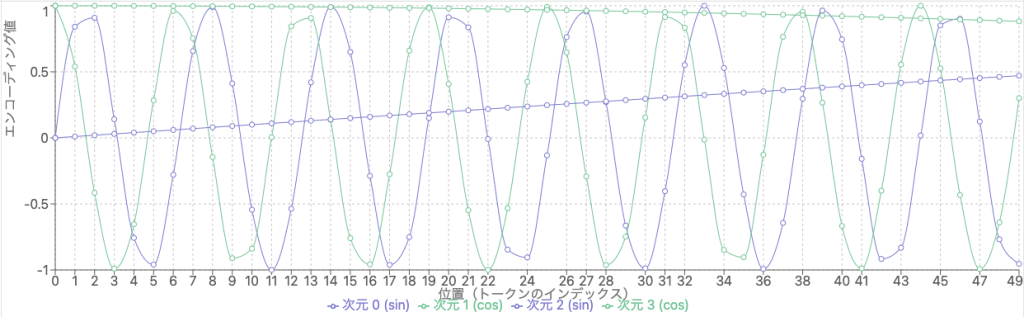
位置エンコーディングの数式を可視化すると、以下のようになります。(4次元の場合)
2.3 埋め込みベクトルとの統合
最終的に、各単語のベクトル表現は以下のように計算されます:
\[\text{最終入力} = \text{単語埋め込み} + \text{位置エンコーディング}\]
この統合により、モデルは単語の意味と順序情報を同時に考慮できるようになります。

