Flutter 音声認識 (Web Speech API/Google Speech)
以前、音声チャットボットアプリを作るために、「Flutter 音声認識」の記事を書きました。
Flutter 音声認識 (speech_to_text)
音声認識パッケージの利用 Flutterアプリの音声認識を実装していきます。Flutterは、様々な機能がパッケージの形で利用可能になっています。従って、実装すると言っても、…

とりあえず、実装はできましたが、Web SpeechAPI,、google_speech(Google Cloud speech-to-text)なども試してみましたので、整理しておきたいと思います。
1)speech_to_text パッケージ
Flutterを使ったモバイルアプリを開発する場合には、先述のspeech_to_textパッケージを使うのがポピュラーな方法です。多くのインターネット記事でこのパッケージを使った方法が紹介されています。
端末の音声認識機能を使いますので、比較的安定して動作しているように思いますが、気になる点もいくつかあります。
このパッケージの紹介文には、以下のように書かれています。
A library that exposes device specific speech recognition capability.This plugin contains a set of classes that make it easy to use the speech recognition capabilities of the underlying platform in Flutter. It supports Android, iOS and web. The target use cases for this library are commands and short phrases, not continuous spoken conversion or always on listening.
デバイス固有の音声認識機能を公開するライブラリ。このプラグインには、Flutter で基盤となるプラットフォームの音声認識機能を簡単に使用できるようにする一連のクラスが含まれています。Android、iOS、ウェブをサポートしています。このライブラリのターゲット ユース ケースは、コマンドと短いフレーズであり、継続的な音声変換や常に聞き取りを行うものではありません。
https://pub.dev/packages/speech_to_text
音声チャットボットの実装方法としては適しているのかと思いますが、連続した音声やファイルを入力とした音声認識には不向きの様です。
また、このパッケージはwebアプリにも対応していますが、パッケージの開発者は、ブラウザの対応について、以下の様に記述しています。
Browser support for speech recognition
Web browsers vary in their level of support for speech recognition. This issue has some details. The best lists I've seen are https://caniuse.com/speech-recognition and https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition. In particular in issue #239 it was reported that Brave Browser and Firefox for Linux do not support speech recognition.
音声認識のブラウザー サポート
Web ブラウザによって、音声認識のサポート レベルが異なります。 この問題にはいくつかの詳細があります。 私が見た中で最も優れたリストは、https://caniuse.com/speech-recognition と https://developer.mozilla.org/en-US/docs/Web/API/SpeechRecognition です。 特に問題 #239 では、Brave Browser と Firefox for Linux が音声認識をサポートしていないことが報告されました。
https://pub.dev/documentation/speech_to_text/latest/
webアプリの場合には”デバイス固有の音声認識機能”として、WebSpeechAPIを使用している様です。webアプリにすることによって、デスクトップ、モバイル端末共通のアプリを作ることを目論んでいましたが、残念ながらiOSのブラウザではうまく動作させることができませんでした。
以上のように、「連続した音声認識に適さない。」「iOS端末のブラウザではwebアプリが動作しない」という2点の問題があります。
そこで、別の方法も試してみることとしました。
2)Web Speech API
まず、Web SpeechAPIそのものを試してみます。ブラウザの対応表を見ると、iOS14.5以降のSafariは対応している様です。
こちらにjavascriptによる実装コードが記載されておりましたので、そのまま利用させていただきます。
Mac OSのchrome、SafariおよびiOSのSafariでも動作することが確認できます。ちなみに、iOSのchromeは非対応です。
WebSpeechAPI オンラインデモ

startボタンを押すと音声認識を開始します。 一定時間の無音があるか、stopボタンを押すことで音声認識を確定します。認識文字列をclearするときには、ページをリロードしてください。
コードは以下の通りです。
<button id="start-btn">start</button>
<button id="stop-btn">stop</button>
<div id="result-div"></div>
<br>
<script>
const startBtn = document.querySelector('#start-btn');
const stopBtn = document.querySelector('#stop-btn');
const resultDiv = document.querySelector('#result-div');
SpeechRecognition = webkitSpeechRecognition || SpeechRecognition;
let recognition = new SpeechRecognition();
recognition.lang = 'ja-JP';
recognition.interimResults = true;
recognition.continuous = true;
let finalTranscript = ''; // 確定した(黒の)認識結果
recognition.onresult = (event) => {
let interimTranscript = ''; // 暫定(灰色)の認識結果
for (let i = event.resultIndex; i < event.results.length; i++) {
let transcript = event.results[i][0].transcript;
if (event.results[i].isFinal) {
finalTranscript += transcript;
} else {
interimTranscript = transcript;
}
}
resultDiv.innerHTML = finalTranscript + '<i style="color:#ddd;">' + interimTranscript + '</i>';
}
startBtn.onclick = () => {
recognition.start();
}
stopBtn.onclick = () => {
recognition.stop();
}
</script>
<br>このように、Javascriptでは動作しますので、Flutterから呼び出すことができるかもしれません。時間ができれば、試してみたいと思います。
3)google_speechパッケージ
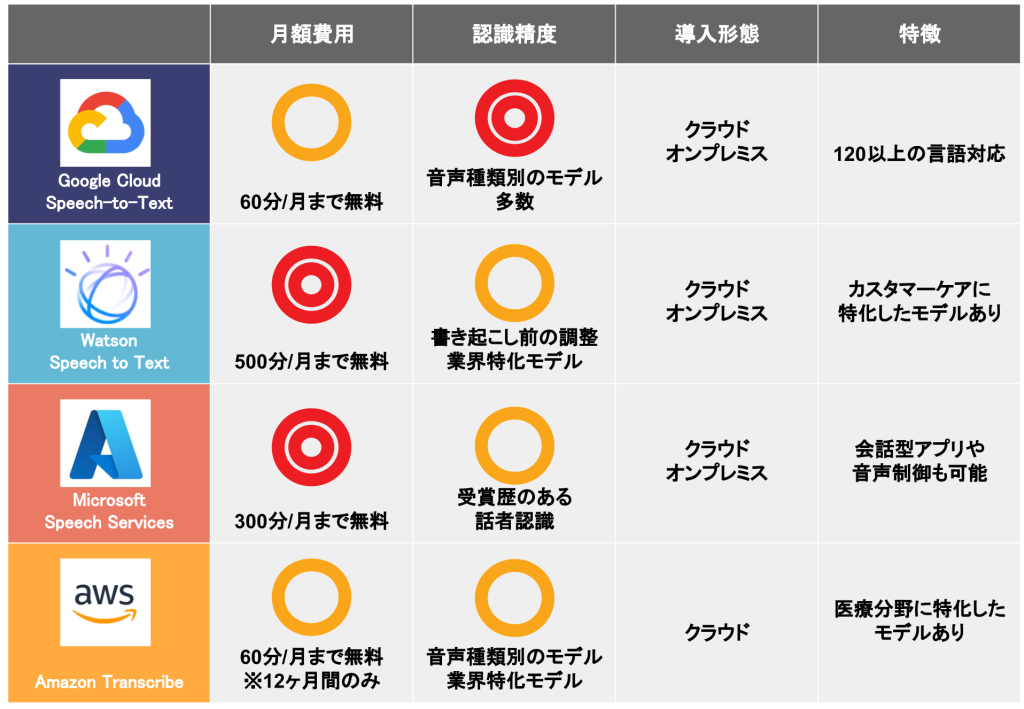
Google、AWS、Azure、IBMといったクラウド大手から、それぞれ音声認識 APIが提供されています。
基本的に有料になりますが、特定用途にカスタムトレーニングして認識精度を向上させたり、話者を識別したりする必要がある場合には、こちらを選択することになるかと思います。また、医療向けなど特定のモデルが用意されたサービスもあります。
クラウドの技術はまさに日進月歩ですので、どれが良いという比較は難しいかと思いますが、こちらのサイトに比較表がありましたので参考までに転記いたします。詳しくは当該サイトをご参照ください。(2022年8月の記事です)
FlutterからCloud音声認識APIを使うためパッケージがないか探したところ、google_speechパッケージが見つかりました。その名の通り、Google Cloud Speech-to-textを使うためのパッケージです。こちらのパッケージでCloud音声認識を試してみたいと思います。
事前準備
利用量に応じて課金されますのでご注意ください。
Google Cloud Platform(GCP)のアカウントを作成して、コンソールにログインします。
ナビゲーションメニューから「APIとサービス」を選択して「有効なAPIとサービス」画面で「Cloud Speech-to-Text API」を選択し、有効にします。
次に、「APIとサービス」ー「認証情報」ー「認証情報を作成」から「サービスアカウント」を作成します。
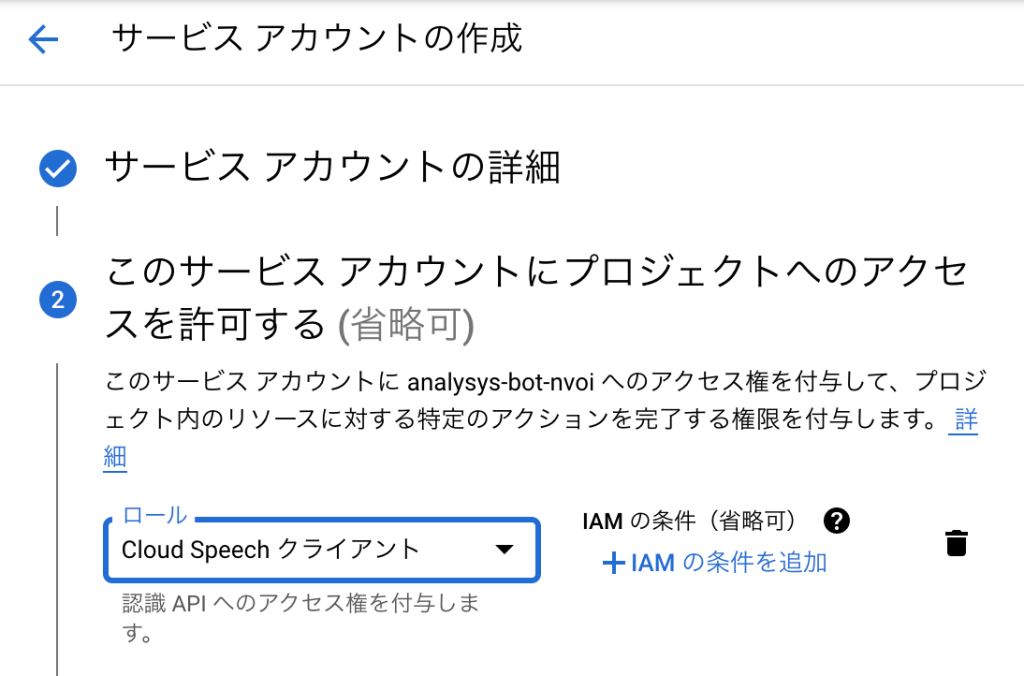
このとき、ロールとして「Cloud Speech クライアント」を付与します。
作成したサービスアカウントの「キー」で「鍵を追加」します。このとき、新しい鍵をJSON形式で作成すると、JSONファイルがダウンロードされます。
google_speech パッケージ
新しくFlutterのプロジェクトを作成し、パッケージをインストールします。
flutter pub add google_speech今回は、マイク入力サンプルを使いますので、必要な以下のパッケージも併せてインストールしておきます。
flutter pub add rxdart
flutter pub add sound_streamiOSの場合は、iOS/Runnerフォルダにあるinfo.plistにマイク入力の許可を加えます。
<key>NSMicrophoneUsageDescription</key>
<string>”アプリがマイクにアクセスする理由”</string>パッケージのmic_stream_exampleからlib/main.dartをコピーして、上書きします。このままでは、英語の認識になっていますので、以下のlanguageCodeを'ja'に変更しておきます。
RecognitionConfig _getConfig() => RecognitionConfig(
encoding: AudioEncoding.LINEAR16,
model: RecognitionModel.basic, // ※1
enableAutomaticPunctuation: true, // ※2
sampleRateHertz: 16000,
languageCode: 'ja');※1 model: RecognitionModel.basic このパッケージで使えるモデルは、以下の通りです。 APIで使えるモデルとは異なります。
/// Which model to select for the given request. Select the model best suited
/// to your domain to get best results. If a model is not explicitly specified,
/// then we auto-select a model based on the parameters in the RecognitionConfig.
enum RecognitionModel {
/// Best for short queries such as voice commands or voice search.
command_and_search,
/// Best for audio that originated from a phone call (
/// typically recorded at an 8khz sampling rate).
phone_call,
/// Best for audio that originated from from video or includes multiple
/// speakers. Ideally the audio is recorded at a 16khz or greater sampling
/// rate. This is a premium model that costs more than the standard rate.
video,
/// Best for audio that is not one of the specific audio models.
/// For example, long-form audio. Ideally the audio is high-fidelity,
/// recorded at a 16khz or greater sampling rate.
basic,
}
※2 enableAutomaticPunctuation: true は、句読点を追加する設定です。
最後に、assetsフォルダを作り、先ほど準備したサービスアカウントのjsonファイルを”test_service_account.json”にリネームして置きます。
pubspec.yamlファイルにassetsを追加しておきます。
# To add assets to your application, add an assets section, like this:
assets:
- assets/test_service_account.json最後にiOSでビルドして端末にインストールします。
flutter build ios
flutter install -d <端末>以上で、実行可能な状態となります。
実行させて、Wikipediaの「音声認識」のページを読み上げて認識させた結果が、以下の通りになります。多少の誤認識はありますが、長文でも途中で止まることなく、認識することができました。句読点をうまく挿入させるためには読み上げ方に慣れが必要なように思います。
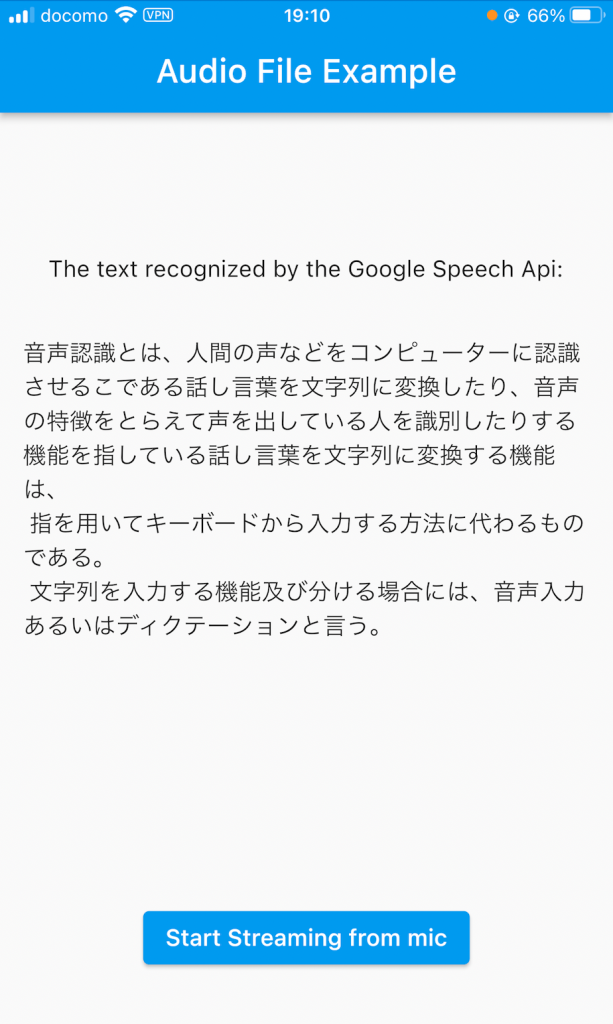
番外)音声入力
音声認識の主な利用用途は、ユーザの入力補助、即ちキーボード入力の代わりとなるものかと思います。モバイル端末の場合には、キーボードに「マイク入力機能」がそもそも備わっているので、アプリ内でわざわざ音声認識機能を実装するよりも、マイク入力機能を使う方が良い場合もあるかと思います。
また、デスクトップPCの場合も認知度は低い様ですが、標準のマイク入力機能が備わっています。テレワーク、ビデオ会議が一般的に行われる様になって、ノートPC以外でもマイクの装着率が上がっているかと思いますので、積極的に利用してみてもいいかもしれません。