自然言語処理モデルを直感的に理解したい(2)OpenAI GPT
前回はTransformerの特徴であるアテンションについて詳しく調べてみました。
自然言語処理モデルを直感的に理解したい(1) Transformer
「ChatGPTはなぜ自然な会話ができる様になったのか?」 多くの人が不思議に思うことだと思います。私はAIの研究者ではなくシステム開発者なので、元となる自然言語処理モ…

今回は、具体的なモデルの例としてOpenAIのGPTについて調べていきます。
OpenAI GPT
OpenAIが開発した初代のGPT(Generative Pre-trained Transformer)は、2018年にリリースされました。
GPTはTransformerアーキテクチャを採用しています。ほぼ同時期にGoogleがBERT(Bidirectional Encoder Representations from Transformers)を発表しています。BERTはTransformerのエンコード部分のみを使っていますが、GPTはほぼオリジナルのTransformerを使っています。
GPTの発表が少し早かったものの、BERTの双方向性がアドバンテージとなり、BERTが広く採用される様になりました。
GPTは主に「次の単語を予測すること」に焦点を当てており、その結果自然な文章を生成することを得意としています。
GPT
GPTは事前学習と、転移学習とを組み合わせることによって、効率的に自然言語処理のタスクを学習することができます。
Improving Language Understanding by Generative Pre-Training
深層学習における事前学習の概念は、2013年ごろに開発されたword2vecで使われていました。このアルゴリズムは、テキストデータから単語間の意味的・文法的な関係を学習し、単語のベクトル表現を生成します。類似の意味を持つ単語はベクトル空間内で近い位置に配置されます。この単語ベクトルは演算もでき、例えば
$$ King - Man + Woman = Queen$$
といった演算ができることが有名です。
GPTモデルの事前学習には、BooksCorpusと呼ばれるデータセットを主に使用しています。BooksCorpusは、約7,000冊の書籍からなるデータセットで、総計8億語を含んでいます。これらの書籍は、さまざまなジャンルをカバーしており、フィクション、ノンフィクション、科学技術、自己啓発などの分野が含まれています。
GPTの事前学習では、与えられた文脈からそれに続く単語を予測できるように学習を繰り返します。
事前学習が完了したモデルは、特定のタスクに適応するように、教師ありの学習データによって転移学習が行われ様々な自然言語処理に適応することができました。
GPT-2
GPT-2は、2019年に以下の論文で発表されています。
Language Models are Unsupervised Multitask Learners
GPT−2の基本コンセプトは、タスクに特化した教師あり学習をするのではなく、様々なタスクに応用できる「汎用的なモデルを構築すること」です。
モデルの構造はGPTとほぼ同じですが、ファインチューニングを不要とするために、モデルの規模を大きくしました。

具体的には、4つのサイズがあり、最大のモデルは48のレイヤーと15億をこえるパラメータを持っています。Table.2の一番小さいモデルが初代のGPTと同じサイズ(12レイヤー、1.17億のパラメータ)です。
学習させるデータセットは40GBのWebTextを使いました。学習データの質を上げるために、特定のWebページに関連するテキストだけを使っています。また、Wikipediaのデータは使われていないとのことです。
GPT-3
GPT-3は2020年に以下の論文で発表されました。
Language Models are Few-Shot Learners
GPT-3のコンセプトはGPT-2と同じです。また、モデルの仕組みもGPT-2から変化ありません。
GPT-3はより大規模モデルをより大きなデータセットで学習させることによって、性能を向上しています。
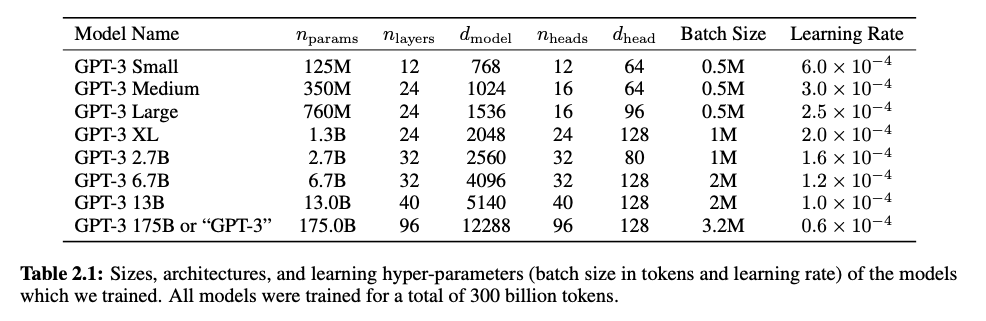
GPT-2では、48のレイヤーと15億のパラメータ でしたが、GPT-3では、96のレイヤーと1750億のパラメータを持っています。
ファインチューニングとfew-shot,
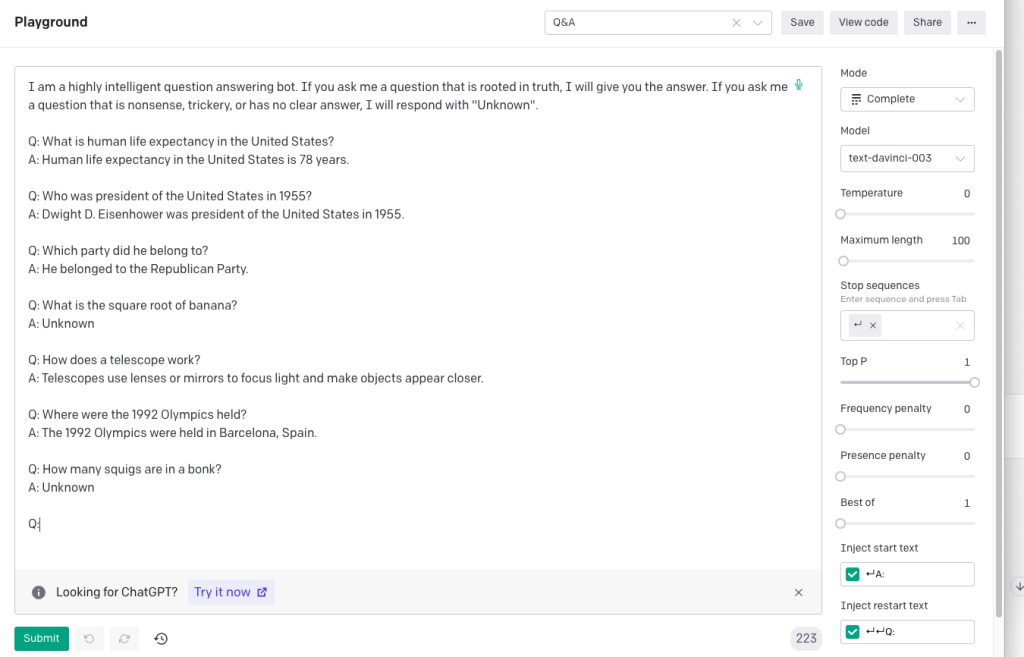
論文タイトルにある”Few -Shot”について、Fig2.1で説明されています。

Few-shotはいくつかの例を与える方法です。ただし、例を与えてもファインチューニングのように学習はしません。
上記の例では、task description によって、「英語からフランス語への翻訳」というタスクが与えられます。それに続いて3つの翻訳例を与えており、最後に prompt で、実際の質問をしています。
Few-shotを知ると、現在のOpenAIのPlaygroundページでLoad a preset..によって出力されるexampleが、同様の形式になっているのがわかります。
まとめ
ここまでの直感的理解は以下の通りとなります。
・ Transformerモデルは、自然言語処理タスクにおける単語の関連性や文章の構造を学ぶためのモデルであり、大規模な学習データを用いて訓練される。学習によって得られたパラメータは、自然言語処理タスクにおける単語の意味表現を含んでいる。
・ Transformerモデルの規模はパラメータ数で表される。パラメータは、ボキャブラリのサイズ、次元数、入力シーケンス長、レイヤー数、アテンションヘッドの数によって決まる。
・ 学習済みのモデルに、入力シーケンスをインプットすると、アテンションメカニズムによって並列で単語間の関連度を重みづけ行列から計算し、どの単語に注意すべきかが数値化される。出力シーケンスを生成する場合には、注意すべき単語を加味しながら、次の単語を予測して出力する。
・ 初代のGPTは大規模な事前学習と転移学習とに分かれており、タスク毎のファインチューニングが必要である。GPT-2以降は汎用的なモデルの構築を目標としていて、そのためモデルの規模を圧倒的に大きくするアプローチが取られた。
