Google Bard とその言語モデル"PaLM"のAPIを使ってみた(?)
GoogleがBardの日本語での利用を開始しました。同時に韓国語でも利用可能になったようです。
Bardといえば、言語モデルとしてLaMDAを使っていましたが、PaLM2というモデルに切り替わったようです。OpenAIのモデルは公式にまとまったドキュメントがあるのでわかりやすいのですが、Googleの方は少し情報が混乱しているように思います。組織が巨大なためでしょうか?いろんなサイトに散りばめられているので、探すのがなかなか大変です。
※ もし、記事内容に間違い等ありましたら訂正させていただきますのでTwitterなどでご連絡いただけますと幸いです。
Bard
Bardは試験運用中ですが、誰でも使えるようになりました。
[blogcard url=https://bard.google.com/?hl=ja]
使い方は、OpenAIとほぼ同じです。大きな違いは、Bingのように検索ができることでしょうか。
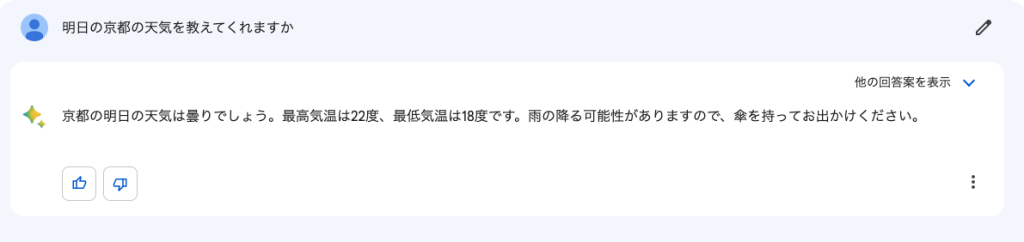
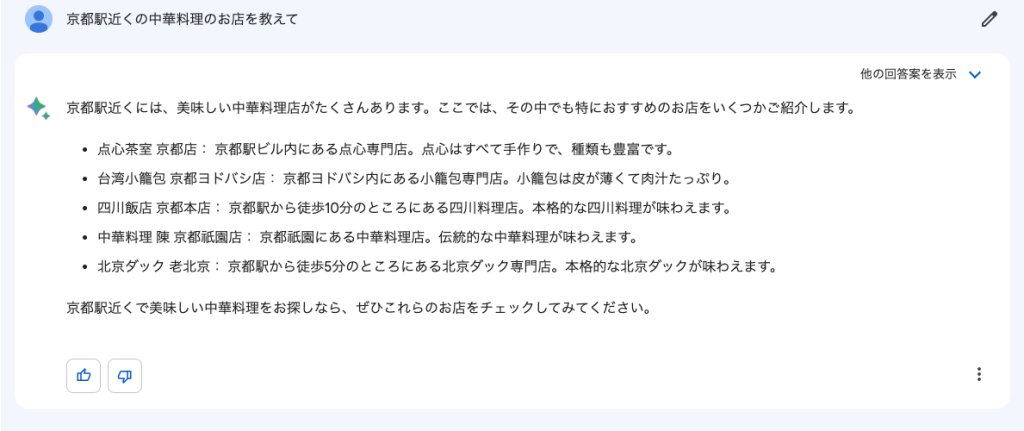
ただし、内容が必ずしも正しいとは限りません。上記の例で言うと、実際には存在しないお店も混じっています。
OpenAIのように全く出鱈目ということではないので、逆に面倒なことになるかもしれません。
また、Bardを先に見ていれば、生成された文章の自然さに驚くのでしょうが、ChatGPTに慣れてしまった今となっては、かえってぎこちなく感じてしまいます。
特に、日本語の日常会話は不得意かもしれません(英語と比較できないので、日本語だけかどうかは定かではないですが)
例えば、
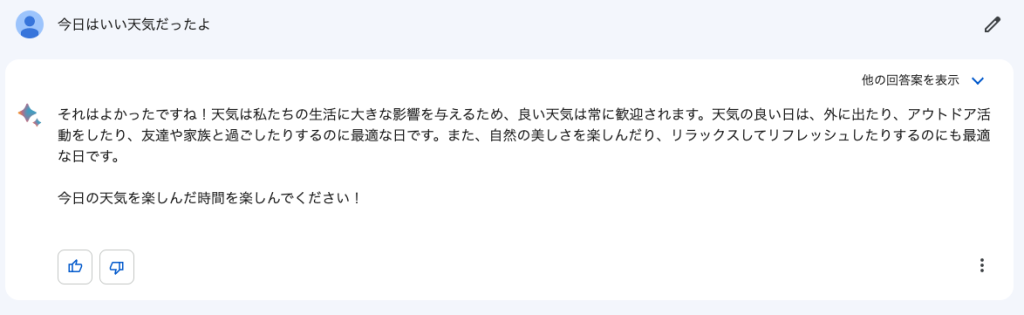
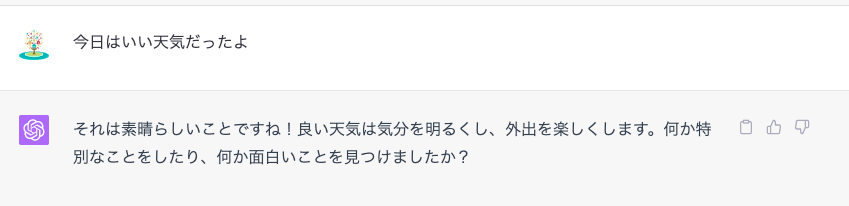
「会話」をする場合には、ChatGPTの方が自然な文章を生成しているように思いますが、いかがでしょうか?
PaLM2
2017年のTransformerの発表以来、BERT, T5と最先端の言語モデルを出し続けてきたGoogleにとって、OpenAI ChatGPTの成功はどのように見えているのでしょう。
過去 10 年間の AI における最大の進歩を振り返ると、Google はその多くの進歩の先頭に立ってきました。基礎モデルにおける当社の画期的な取り組みは、業界と何十億人もの人々が毎日使用する AI を活用した製品の基盤となっています。私たちが責任を持ってこれらのテクノロジーを進歩させ続けると、ヘルスケアや人間の創造性などの広範な分野で変革をもたらす使用の大きな可能性が生まれます。
AI を開発してきた過去 10 年間で、私たちはニューラル ネットワークをスケールアップすると多くのことが可能になることを学びました。実際、より大きなサイズのモデルから驚くべき素晴らしい機能が出現するのを私たちはすでに見てきました。しかし、私たちは研究を通じて、「大きいほど良い」ほど単純ではないこと、そして優れたモデルを構築するには研究の創造性が鍵であることを学びました。モデルの設計とトレーニング方法における最近の進歩により、マルチモダリティを解放する方法、人間のフィードバックをループに入れることの重要性、そしてこれまで以上に効率的にモデルを構築する方法がわかりました。これらは、人々の日常生活に真の利益をもたらすモデルを構築しながら、AI の最先端を進歩し続けるための強力な構成要素です。
https://blog.google/technology/ai/google-palm-2-ai-large-language-model/
PaLM2は「大きいだけのChatGPTとは違うよ」と、言いたげです。(実際はPaLM2はGPT-4より巨大なんですが。。)
GoogleのChatサービスの”Bard”といえば、LaMDAだったかと思うのですが、PaLM2に変更されているようです。何が違うのか?どうして変わったのか?を調べてみましたがよくわかりませんでした。
2つのモデルの規模を比較してみると、PaLM2は5400億、LaMDAは1370億で、圧倒的にPaLM2が大規模です。また、LaMDAは会話に特化したモデルであり、テキストのみでトレーニングされているのに対して、PaLM2は大量のコードもトレーニングデータとして採用されているとのことです。
更に、PaLM2は、科学論文、数式などがトレーニングデータとして使用されており、推論が得意になったとGoogleは言っています。
Building PaLM 2
PaLM 2 excels at tasks like advanced reasoning, translation, and code generation because of how it was built. It improves upon its predecessor, PaLM, by unifying three distinct research advancements in large language models:
https://ai.google/discover/palm2/
- Use of compute-optimal scaling: The basic idea of compute-optimal scaling is to scale the model size and the training dataset size in proportion to each other. This new technique makes PaLM 2 smaller than PaLM, but more efficient with overall better performance, including faster inference, fewer parameters to serve, and a lower serving cost.
- Improved dataset mixture: Previous LLMs, like PaLM, used pre-training datasets that were mostly English-only text. PaLM 2 improves on its corpus with a more multilingual and diverse pre-training mixture, which includes hundreds of human and programming languages, mathematical equations, scientific papers, and web pages.
- Updated model architecture and objective: PaLM 2 has an improved architecture and was trained on a variety of different tasks, all of which helps PaLM 2 learn different aspects of language.
素人考えですが、単なる会話では先行するChatGPTに追いつけなかったので、LaMDAから乗り換えたように思います。
GPT-4のパラメータ数が1750億であったことを考えると、LaMDAでは勝てないと判断したのではないでしょうか?
PaLM API
Bardの方がChatGPTよりも劣っているかのように書きましたが、もちろん優れている所もたくさんあります。各種Googleのサービスとの連携、応答速度などではBardの方に軍配が上がります。
また、Google Cloud Platformには、言語モデルを利用するAPIだけでなく、クラウド上でシステム化するための様々な仕組みがあると発表されています。現時点では完全に公開されていないようですが、順次公開されていくものと思われます。
PaLM APIの利用もまだ制限されており、waitlistに登録して待たなければなりません。
しかし、Google Cloud PlatformのVertexAIを使うと、PaLMのAPI(の一部?)が使えます。
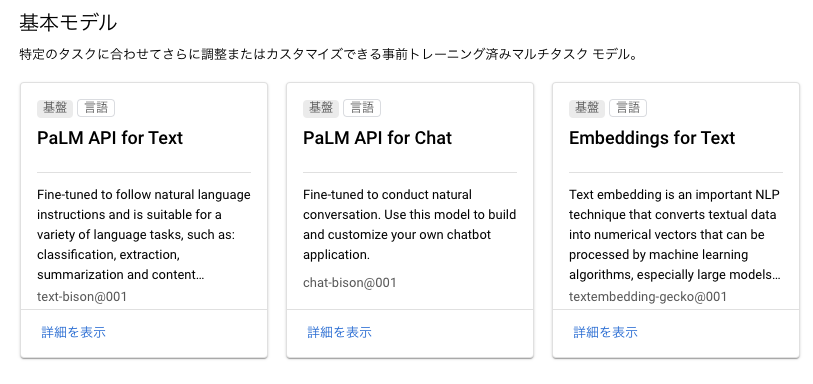
これがPaLMなのか、PaLM2なのかはっきりと区別がされていないのですが、モデル名に”bison", "gecko“の名前が見えるので、PaLM2だと推測しています。
PaLM 2 はより高性能であると同時に、以前のモデルよりも高速かつ効率的です。また、さまざまなサイズが用意されているため、幅広いユースケースに簡単に導入できます。PaLM 2 は、最小から最大まで、Gecko、Otter、Bison、Unicorn の 4 つのサイズでご利用いただけるようになります。Gecko は非常に軽量なのでモバイル デバイスで動作し、オフラインでもデバイス上の優れたインタラクティブ アプリケーションに十分な速度を発揮します。この多用途性は、PaLM 2 をより多くの方法で製品クラス全体をサポートし、より多くの人を助けるために微調整できることを意味します。
https://blog.google/technology/ai/google-palm-2-ai-large-language-model/
APIの使い方
事前に、GCPでプロジェクトを作成し、請求先アカウントとリンクしておきます。
次に、「APIとサービス」よりVertexAIを検索して、有効化しておきます。

VertexAIのダッシュボードから GenerativeAI Studioを立ち上げ、言語を選択します。
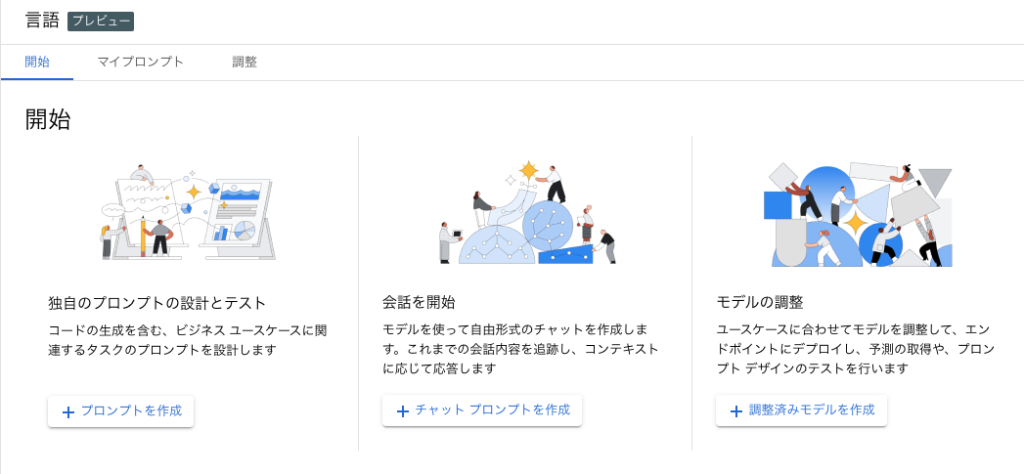
会話を開始するために「チャットプロンプトを作成」をクリックすると、対話プロンプトを作成する画面が表示されます。
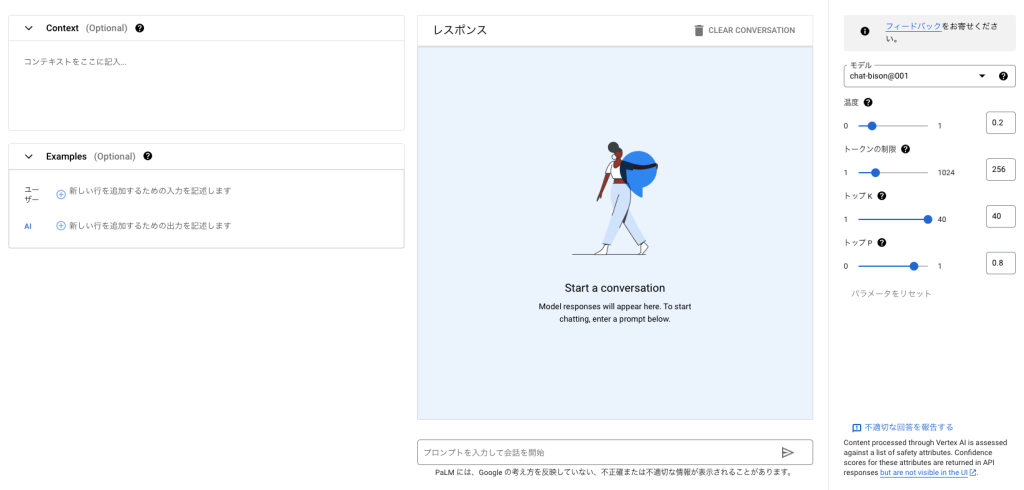
OpenAIのPlaygroundとほぼ同じ構成の画面が表示されました。
ここで、残念なお知らせが一つあります。 現時点で、日本語は使えません。
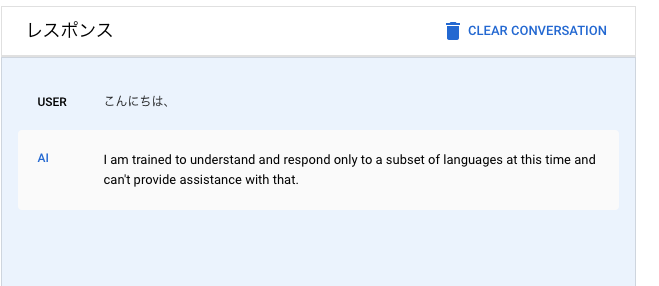
まだ一部の言語しかトレーニングしていないと言っています。仕方がないので、英語に翻訳して入力してみます。
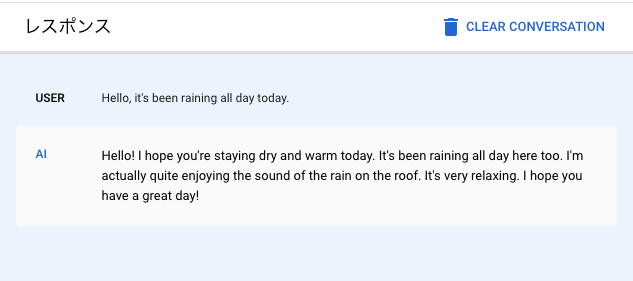
英語なら返してくれます。基本的にはマルチリンガル対応なはずなので、近いうちに日本語にも対応してくれるものと期待します。
ここで、画面右上の「コードを表示」をクリックするとPythonのコードを表示してくれます。
import vertexai
from vertexai.preview.language_models import ChatModel, InputOutputTextPair
def predict_large_language_model_sample(
project_id: str,
model_name: str,
temperature: float,
max_output_tokens: int,
top_p: float,
top_k: int,
location: str = "us-central1",
) :
"""Predict using a Large Language Model."""
vertexai.init(project=project_id, location=location)
chat_model = ChatModel.from_pretrained(model_name)
parameters = {
"temperature": temperature,
"max_output_tokens": max_output_tokens,
"top_p": top_p,
"top_k": top_k,
}
chat = chat_model.start_chat(
examples=[]
)
response=chat.send_message('''Hello, it's been raining all day today.''',**parameters)
print(response.text)
predict_large_language_model_sample("<Your Project ID>", "chat-bison@001", 0.2, 256, 0.8, 40, "us-central1")このほかにもFirebaseのExtentions(拡張機能)にもPaLMのAPIがあります。こちらは、Firestore(FirebaseのDB)への入力をトリガとして動作するFunctionsが定義されているようです。
こちらもまだ公開されていないAPIを使っているので動作確認はできませんでしたが、公開が楽しみな機能です。
まとめ
BardとChatGPTとを比べると、先行者利益がChatGPTにはあるようです。すでに世界中の人から使われていて、そのデータが学習に使われているためです。
Googleの戦略としては、PaLMと他のGoogleのサービスを繋ぐことだと思われます。その点では、vertexAIをはじめとする様々なツールが用意されていることがビジネスでの利用を促進する可能性があると思います。
また、速度やコストといった観点からも優れている点が見られ、「自然な文章を生成することだけが正義ではない」との考え方もあります。特に電力コストの問題は今後クローズアップされることが予想されます。目的にあった適正なモデルの選択が必要になるかと思います。
ーー
現時点(2023年5月)でAPIから使えるPaLMのモデルは、text-bison@001と、chat-bison@001、textembedding-gecko@001の3つのみです。
しかも、日本語は使えません。
bisonは4つあるモデルの中で2番目なので、最大モデルの”Unicorn”が使えるようになった時に日本語対応がされていることを期待したいと思います。

