sentenceBERTによる分類例
音声チャットボットの開発では、応答を生成するために、事前学習済みのT5モデルに、対話データを学習させました。
応答生成モデルの学習(Text-to-Text Transfer Transformer)
ユーザの発話テキストに対して、応答テキストを生成させるためのモデルを作ります。 T5 (Text-to-Text Transfer Transformer) チャットボットを作るときに必要となるモデ…

このモデルは、どんな話題をしているのかを理解しているわけではありません。条件反射的にそれらしい応答を返しているだけです。
しかし、チャットボットを有用な対話システムとして利用する際には、ユーザの発話データを分析し、理解することが不可欠です。ここでは、非タスク指向型のチャットボットのデータを想定して、ユーザの状態を推定することを考えてみたいと思います。
まず、最初の試みとして、話題と感情とをそれぞれを分けて分析し、組み合わせてユーザの状態を推定します。
話題推定
ここでの話題推定の出力は、要約ではなく、あらかじめ定められたカテゴリに分類することとします。話題推定の結果を利用することを考えると、要約よりも分類の方がその後の処理で使いやすそうだからです。
カテゴリ分類のよくある例として、ニュースのカテゴリ分類があります。これは、実際のニュースデータとそのカテゴリの組み合わせを学習させる手法です。livedoorのデータが日本語コーパスとしてよく使われています。
既に分類済みのデータがたくさんある場合には良いのですが、対話データを集めて手動で分類することはかなり大変そうです。そこで、以下の方法を試してみました。
文章類似度
カテゴリに分類するということは、言い換えると、「類似する文章をまとめる」ということになります。例えば、話題A,B,Cの3つの話題に分類したい場合には、A,B,Cそれぞれの代表するベクトルを求めておき、入力された文章が、どのベクトルと一番近いかを計算すれば良いと考えました。
ここで、問題となるのは「カテゴリを代表するベクトルをどう定義するか?」ということです。
そこで、各カテゴリを表すような単語ベクトルを複数求め、その平均ベクトルを代表ベクトルとする方法を考えましたので実際に計算して可視化してみます。
文章類似度の計算のモデルとして、Sentence Similarity というタスクを実行するためのモデルがあります。今回は、日本語の学習済みモデルとして、colorfulscoop/sbert-base-ja を使います。
カテゴリデータ
カテゴリは、以下の11に分類することとし、それぞれのカテゴリに関連する単語を設定しました。総数は134単語です。
- 病院
- 病気
- 趣味
- 仕事
- 学校
- 家事
- 社会
- 経済
- 家計
- 天候
- 家族
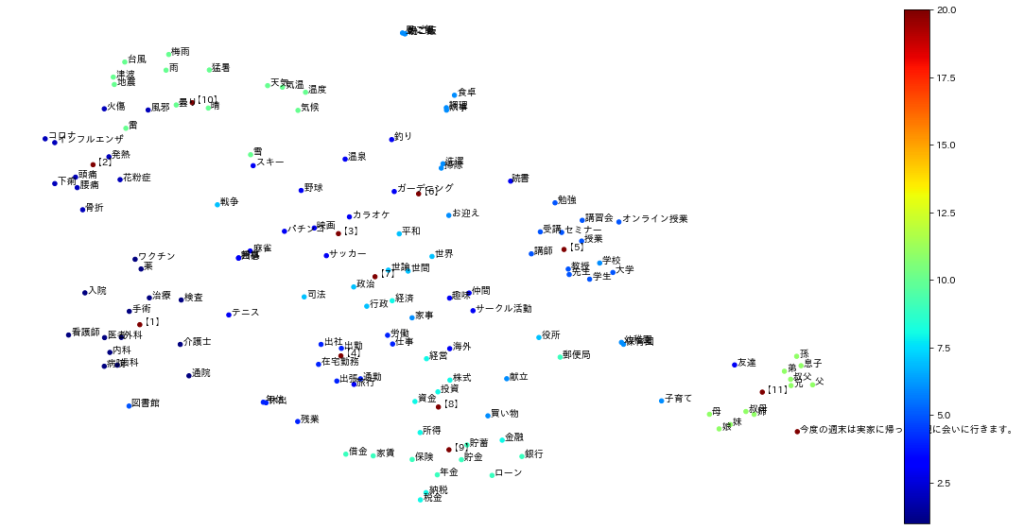
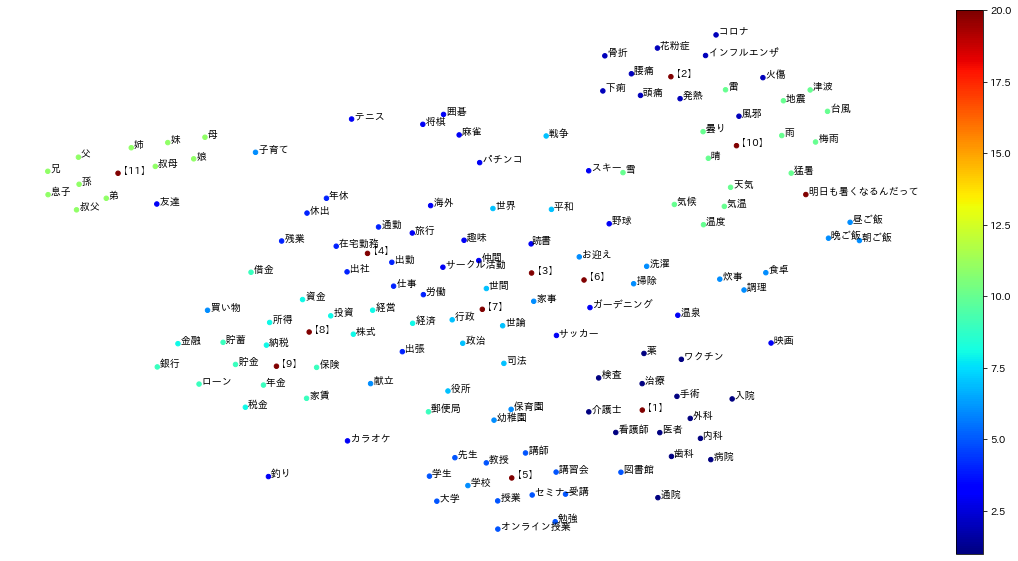
各カテゴリに含まれる単語ベクトルとその代表点【 n 】ベクトルとを可視化した結果は以下の通りです。
#可視化のためにt SNEを使って次元削減しています。

各カテゴリ単語の中心あたりに代表ベクトルが存在しているのが分かります。
結果
文章ベクトルを加えてプロットしてみます。
例1)「今度の週末は実家に帰って両親に会いに行きます」
【11】家族の代表ベクトルの近くにプロットされました。
例2)「明日も暑くなるんだって」
【10】天候の代表ベクトルの近くにプロットされました。
まとめ
話題推定にsentence BERTをベースとしたモデルを使ってみました。直感的に理解するために、文章ベクトルの可視化を行い、代表ベクトルとの距離を計算することによって、話題推定ができそうな感触を得ました。
ただし、tSNEで次元削減していますので、実際には元の次元数で計算する必要があります。また、今回は可視化のために単語量をある程度絞りましたが、代表ベクトルを決めるための単語量を増やした上で、定量的な手法の評価が必要かと考えています。
参考サイト
https://www.softbanktech.co.jp/special/blog/dx_station/2022/0032/
