Difyを使ってRAGの機能を試してみた
生成AIの弱点の一つはハルシネーション(幻覚)を起こしてしまうことです。もっともらしい”ウソ”をつくので騙されてしまうこともあり得ます。
RAGはRetrieval-Augmented Generation の略で検索拡張生成などとも言われます。正しい情報を予めインプットしてDB化しておき、検索と生成の二つのプロセスを経て正しい回答を返すというものです。(OpenAI社のAssistat APIも同じような仕組みかと思われます)
これによって、特定分野の知識を”再学習”させることなく、専門的な知識を回答に反映させることができます。
ナレッジの登録
Difyではナレッジのデータソースとして、以下の三つがあります。
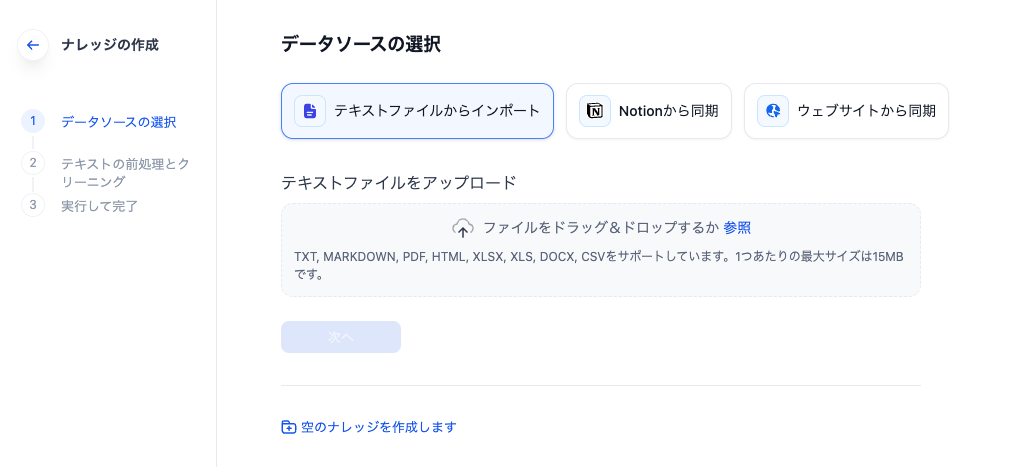
今回はテキストファイルからのインポートを選択しました。
インポートするテキストファイルとして、RAGの効果がはっきりわかるように(間違っているかどうかが判断できるように)、NHK天気予報のテキスト版を使いました。
京都京都下京区のページを表示させて、このページをpdf化し、先ほどの画面からアップロードします。
ちなみに、テキスト版以外のページだと表や画像が含まれていて、正しくナレッジ化できない可能性があるようです。ファイル形式はさまざまな形式をサポートしていますが、ナレッジにする段階で誤ってしまうといけませんので、できるだけ平文のテキストが良いかと思います。
次に、「テキストの前処理とクリーニング」を行いますが、これはすべてデフォルトで行いました。
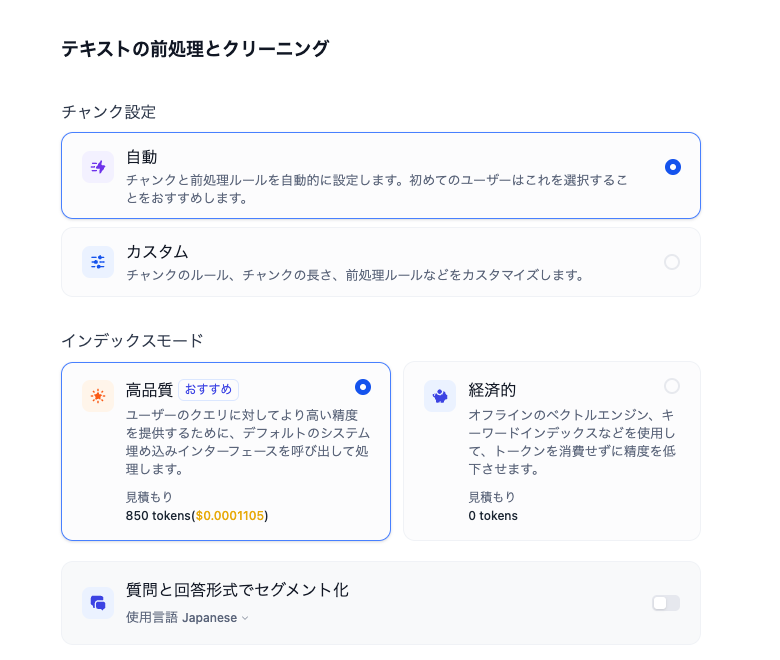
「保存して処理」をクリックすると、ナレッジの完成です。
Chatflowの作成
前回の記事では、基本のチャットボットを作成しましたが、今回は、Chatflow使います。
出来上がったChatflowのLLMの前に「知識取得」を挿入します。
知識取得を選択して、ナレッジに先ほど追加したドキュメントを追加します。
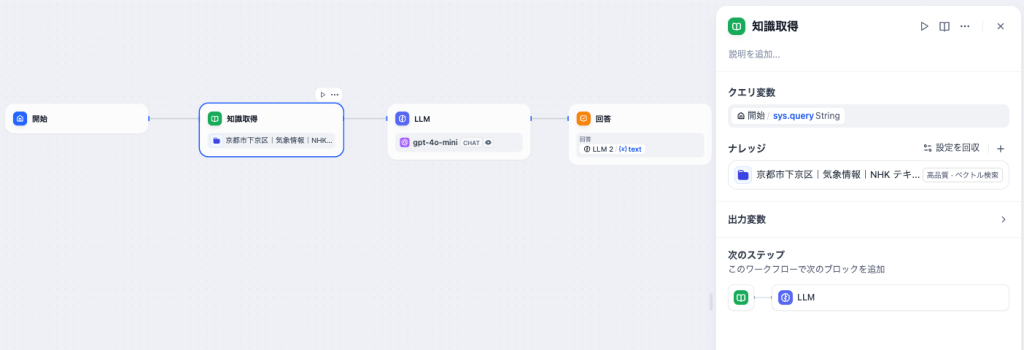
LLMでは、コンテキストに「知識取得」のresultを追加し、コンテキストを使って、SYSTEMプロンプトを記述します。
また、会話の履歴を使って回答ができるように、「メモリ」もONにしておきます。
結果
アプリケーションを実行してみました。
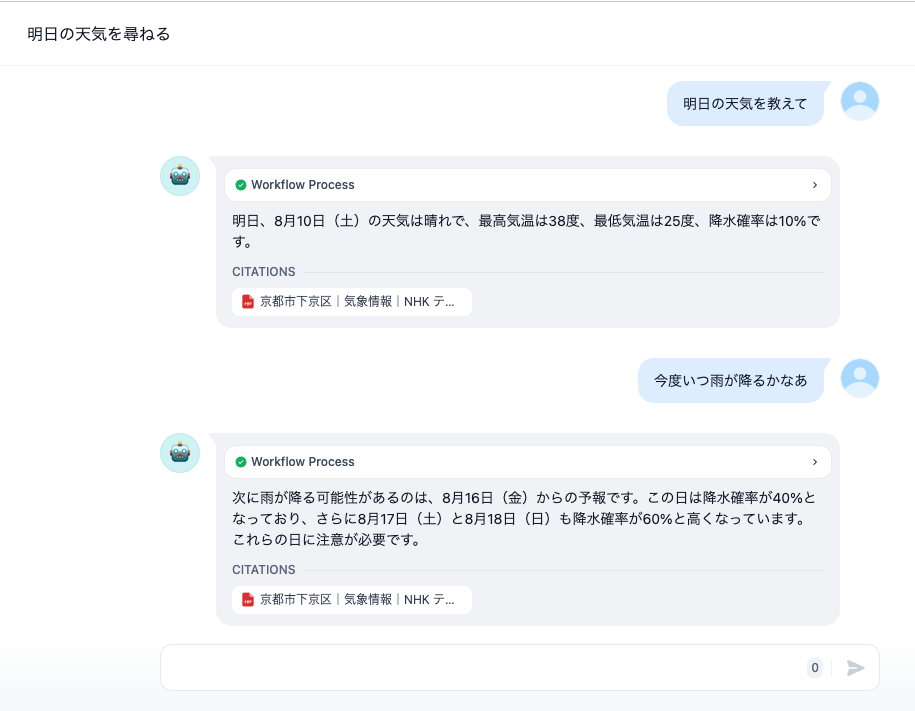
残念ながら、「明日の天気」を聞いたのですが、この最高気温、最低気温は「今日の天気」のものでした。降水確率については、正しい回答をした様です。
間違えた原因を考えたところ、WebページそのままをPDF化したことかと思います。
そこで、PDFのテキスト部分を抜き出し、手動で整形しました。具体的には、区切り線(ーー)を各データの間に入れて、日付とお天気データとの関係を明確にしました。すると、以下の様に正しい回答を得ることができました。
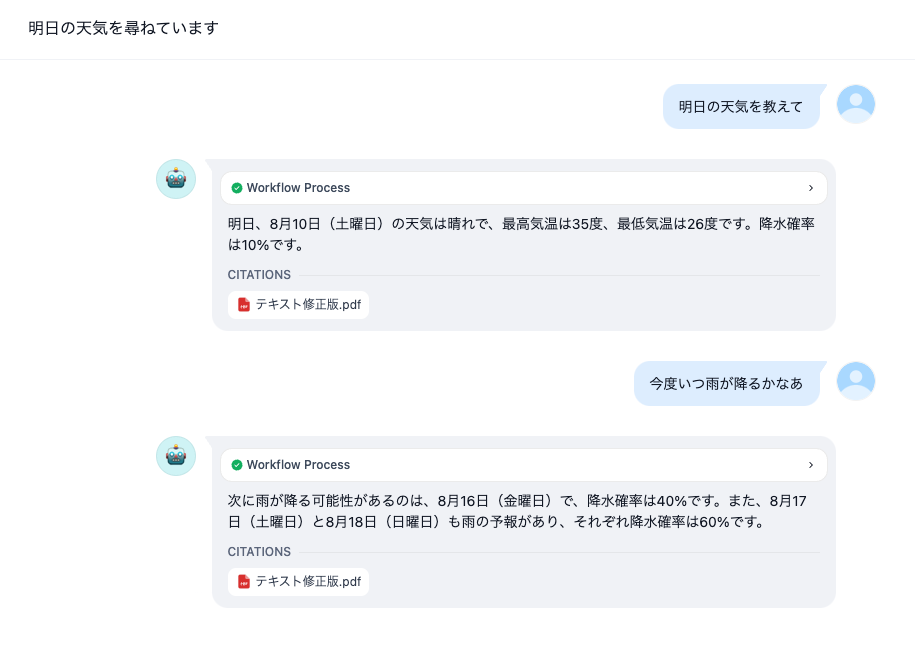
今回は、入力したテキストファイルが「文章」ではなく天気や気温などの「ワード」の羅列であったため、ワード間の関係性がわかりにくかったことが直接の「原因であると考えています。
一般的なドキュメントであればこのような問題は起きないかもしれませんが、元となるファイルは前処理で整形しておいた方が良さそうです。

