PyCaret を使ってデータの分類問題をやってみた
データ分析の中で、最も初歩的な分類問題を、PyCaretを使ってやってみました。
データの準備
今回は、Kaggleにあったビギナー用のデータをダウンロードして使っています。
[blogcard url= "https://www.kaggle.com/datasets/ahmettezcantekin/beginner-datasets"]
このデータは、
from pycaret.datasets import get_data
data_df = get_data('<データ名>') でも使えるようになりますが、一般的にするためにcsvファイルを読み込むようにしました。
多くのデータファイルが含まれていますが、その中から、Default TaskがClassification (Binary)の'bank.csv'を選んで二値分類してみます。
基本的な使い方
まずはライブラリをインストールします。
pip install pycaret基本的な処理の流れは、以下のとおりです。
# ライブラリのインポート
from pycaret.classification import *
import pandas as pd
# 学習データを読み込む
train = pd.read_csv('train.csv', sep=',')
# セットアップ trainのlabel列が 1 or 0 の目的変数です
exp1 = setup(data=df, target='label', session_id=123)
# モデル比較
best_model = compare_models()
# モデルのトレーニング
model = create_model(best_model)
# モデルの調整
tuned_model = tune_model(model)
# モデルの評価
evaluate_model(tuned_model)
# 予測したいデータの読み込み
test = pd.read_csv('test.csv', sep=',')
# モデルの予測
predictions = predict_model(tuned_model, data=test)
# 予測結果の保存
predictions.to_csv('predictions.csv',index=False,header=False)
# モデルの保存
save_model(tuned_model, 'モデルの保存名')
bank.csv
まずは、データを読み込みます。
ダウンロードしたデータはGoogleDriveに入れておき、GoogleColabからドライブをマウントして使います。
import pandas as pd
filename = '/content/drive/MyDrive/work/beginner_datasets/bank.csv'
data = pd.read_csv(filename, sep= ',')ちなみに、大量のデータ(例えば数万枚の画像データ)の場合には、この方法ではうまくいかないことがあります。(学習の途中で画像が見つからないというエラーが出てしまいました)
その時には、GoogleColabの"/content"配下に圧縮データをコピーしてそこで解凍(unzip)することで解決できます。ただし、この方法だとランタイムを再起動するたびにコピー&解凍という作業が必要となってしまうのが難点ですが。。
どんなデータが入っているのか確認します。
data.info()
-
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 45211 entries, 0 to 45210
Data columns (total 17 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 age 45211 non-null int64
1 job 45211 non-null object
2 marital 45211 non-null object
3 education 45211 non-null object
4 default 45211 non-null object
5 balance 45211 non-null int64
6 housing 45211 non-null object
7 loan 45211 non-null object
8 contact 45211 non-null object
9 day 45211 non-null int64
10 month 45211 non-null object
11 duration 45211 non-null int64
12 campaign 45211 non-null int64
13 pdays 45211 non-null int64
14 previous 45211 non-null int64
15 poutcome 45211 non-null object
16 deposit 45211 non-null object
dtypes: int64(7), object(10)
memory usage: 5.9+ MB
bank.csvの目的変数はdepositということになっています。
ただ、depositが"yes"/"no"の文字列を値に持っているので、バイナリ分類するために、1,0にマッピングしてからデータの setupを行います。
mapping = {"yes": 1, "no": 0}
data['deposit'] = data['deposit'].map(mapping)from pycaret.regression import *
e = setup(data=data, target='deposit', session_id=123)次はモデルの比較です。コマンド一つで、複数のモデルを評価できます。
# モデル比較
best_model = compare_models()何も指定しなければ、Accuracy の高い順にソートします。
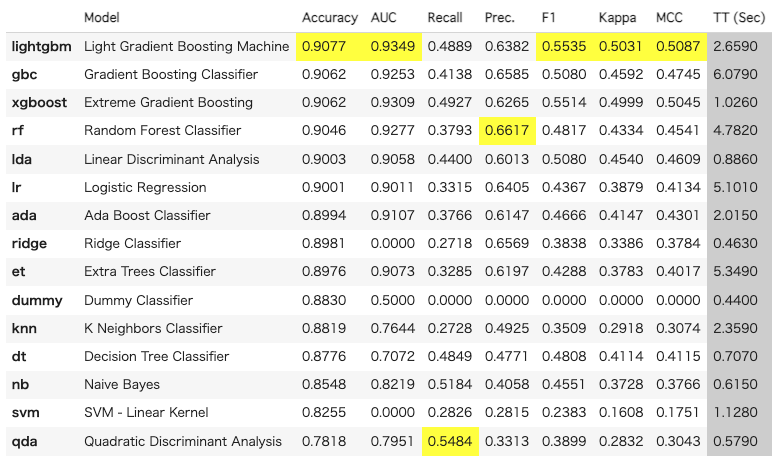
他の指標でソートする時には、sortオプションで指定します。
"F1を使ってソート
best_model = compare_models(sort = 'F1')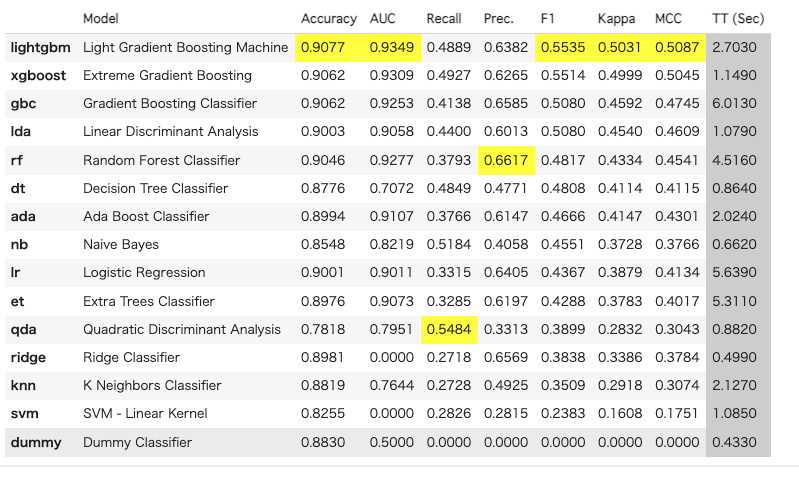
今回は、最適なモデルがlightgbmだったので、ハイパーパラメータを調整してみます。
tuned_model = tune_model(best_model)
調整前後のハイパーパラメータの値を確認してみます。
# default model
print(best_model)
# tuned model
print(tuned_model)
--
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=10, reg_alpha=0.0, reg_lambda=0.0, subsample=1.0,
subsample_for_bin=200000, subsample_freq=0)
LGBMClassifier(boosting_type='gbdt', class_weight=None, colsample_bytree=1.0,
importance_type='split', learning_rate=0.1, max_depth=-1,
min_child_samples=20, min_child_weight=0.001, min_split_gain=0.0,
n_estimators=100, n_jobs=-1, num_leaves=31, objective=None,
random_state=10, reg_alpha=0.0, reg_lambda=0.0, subsample=1.0,
subsample_for_bin=200000, subsample_freq=0)変化がないように見えますね。tune_modelのパラメータにでさらに調整する必要があるのかもしれません。
例えば、イテレーション回数を増やすこともできます。
tuned_model2 = tune_model(best_model, n_iter=50)また、pycaretの公式ドキュメントには以下のような記載がありました。
Automatically choose better
Often times the
https://pycaret.gitbook.io/docs/get-started/functions/optimize#automatically-choose-bettertune_modelwill not improve the model performance. In fact, it may end up making performance worst than the model with default hyperparameters. This may be problematic when you are not actively experimenting in the Notebook rather you have a python script that runs a workflow ofcreate_model-->tune_modelorcompare_models-->tune_model. To overcome this issue, you can usechoose_better. When set toTrueit will always return a better performing model meaning that if hyperparameter tuning doesn't improve the performance, it will return the input model.
tune_modelでは改善されない場合があり、むしろ悪くなってしまうケースがあるようなので、choose_betterオプションをつけた方が良さそうです。
choose_betterのサンプルコードは、以下のとおりです。
# load dataset
from pycaret.datasets import get_data
boston = get_data('boston')
# init setup
from pycaret.regression import *
reg1 = setup(boston, target = 'medv')
# train model
dt = create_model('dt')
# tune model
dt = tune_model(dt, choose_better = True)次にモデルの評価をしてみます。
evaluate_model(tuned_model)様々な評価値が可視化されます。ここでは、ConfusionMatrixを表示しています。

アンサンブル
最後に複数のモデルを組み合わせるアンサンブルを試してみます。必ずしもアンサンブルをすれば良い結果になるというわけではないようですが、kaggleなどでは一般的に行われている手法です。
組み合わせ方にもいろいろあるようですが、pycaretでは、ブレンドモデルとスタッキングモデルが簡単に構築できます。
どのモデルを組み合わせたら良いのかは、試してみないとわからないのですが、compare_modelsの上位モデルで、違うタイプのものを試してみると良いようです。
とりあえず、lightgbm, gbc, rtを使ってみます。
ブレンドモデル
ブレンドモデルは、複数のモデルを組み合わせて使います。組み合わせ方は、methodオプションで指定します。予測確率を平均かする場合は、'soft'を指定し、予測結果を多数決で決める場合には、'hard'を指定します。
#ベースとなるモデルをcreateする
lightgbm = create_model('lightgbm')
gbc = create_model('gbc')
rt = create_model('rt')
#それぞれのモデルを調整する
lightgbm = tune_model(lightgbm)
gbc = tune_model(gbc)
rt = tune_model(rt)
#ブレンドする
blend_model = blend_models(estimator_list = [lightgbm,gbc,rt], method = 'soft')
スタックモデル
スタックモデルは、メタモデルに、どのモデルの予測値が良いのかを学習させる方法です。ブレンドモデルの結果のブレンド方法を学習させるというイメージでしょうか。(まだしっくりきていませんが。。)
#ベースとなるモデルをcreateする
lightgbm = create_model('lightgbm')
gbc = create_model('gbc')
#それぞれのモデルを調整する
lightgbm = tune_model(lightgbm)
gbc = tune_model(gbc)
#メタモデルをcreateする
rf = create_model('rf')
#スタックする
stacker = stack_models(estimator_list = [lightgbm,gbc], meta_model = rf)
結果
結果は以下のようになりました。
Accuracy AUC Recall Prec. F1 Kappa MCC lightgbm平均 0.9073 0.9296 0.4560 0.6478 0.5350 0.4852 0.4946 ブレンドモデル平均 0.9078 0.9358 0.4260 0.6663 0.5195 0.4712 0.4858 スタックモデル平均 0.9071 0.9339 0.4846 0.6350 0.5495 0.4988 0.5045

