Transformerの仕組みを体系的に理解したい 第3章
第3章: Attention機構の仕組み
Transformerの革新の中心となるのがAttention機構です。特に、Self-Attention(自己注意メカニズム)は、入力文中の単語間の関係をモデル化するための鍵となる仕組みです。この章では、Attentionとは何かを基礎から説明し、Self-AttentionおよびMulti-Head Attentionの詳細を数式とともに解説します。
3.1 Attentionとは何か?
Attentionは、「ある単語が他の単語にどれだけ関連しているかを計算し、その重要度に応じて情報を再構成する仕組み」です。TransformerにおけるAttentionは、入力文のすべての単語間の関係をモデル化することで、文脈を正確に理解する能力を提供します。
例えば、以下の文を考えます:
「犬は庭でボールを追いかけている」
この文において、「追いかけている」という動詞と「犬」や「ボール」という名詞は密接な関係があります。一方で、「庭」と「追いかけている」の関係は弱いかもしれません。Attentionは、このような単語間の関連性を計算し、文脈を効率よく捉える仕組みです。
3.2 Scaled Dot-Product Attentionの計算過程
Attentionの計算の中心となるのがScaled Dot-Product Attentionです。このメカニズムでは、各単語のQuery(クエリ)、Key(キー)、Value(バリュー)の3種類のベクトルを用いて計算を行います。
以下、計算の手順を順を追って説明します。
1. Query、Key、Valueとは?
各単語には、以下の3種類のベクトルが割り当てられます:
- Query(クエリ):\(\boldsymbol{q_i}\)
→ 対象の単語が他の単語に対して「どれくらい注意を払うか」を表すベクトル。 - Key(キー):\(\boldsymbol{k_j}\)
→ 他の単語が対象の単語を参照する際の「指標」となるベクトル。 - Value(バリュー):\(\boldsymbol{v_j}\)
→ 実際に「情報の内容」を保持するベクトル。
これらは、以下のように学習可能な重み行列を用いて入力ベクトルから生成されます:
\[\boldsymbol{Q} = \boldsymbol{X} \boldsymbol{W}_Q, \quad \boldsymbol{K} = \boldsymbol{X} \boldsymbol{W}_K, \quad \boldsymbol{V} = \boldsymbol{X} \boldsymbol{W}_V\]
ここで:
- \(\boldsymbol{X}\):入力ベクトル(単語埋め込み)。
- \(\boldsymbol{W}_Q, \boldsymbol{W}_K, \boldsymbol{W}_V\):学習可能な重み行列。
2. スコアの計算(QueryとKeyの内積)
各単語のクエリベクトル(\(\boldsymbol{q}_i\))と他のすべての単語のキー(\(\boldsymbol{k}_j\))との内積を計算します。これにより、単語間の関連度(スコア)が得られます:
\[\text{Score}_{ij} = \boldsymbol{q}_i \cdot \boldsymbol{k}_j\]
内積を使う理由は、2つのベクトルの方向が一致しているほど値が大きくなるためです。つまり、「クエリ」と「キー」が似ているほど、関連度が高いと判断されます。
3. スコアのスケーリング
スコアをそのまま使用すると、キーの次元数(\(\boldsymbol{k}_jの次元数:\boldsymbol{d}_k\))が大きい場合、値が大きくなりすぎる可能性があります。そのため、スコアを次元数の平方根で割ってスケーリングします:
\[\text{Scaled Score}_{ij} = \frac{\boldsymbol{q}_i \cdot \boldsymbol{k}_j}{\sqrt{d_k}}\]
4. スコアの正規化(Softmax)
次に、スコアをSoftmax関数で正規化し、各単語間の「注意の重み」を計算します。Softmaxはスコアを確率分布(0〜1の範囲)に変換します:
\[\alpha_{ij} = \text{softmax}\left(\frac{\boldsymbol{q}_i \cdot \boldsymbol{k}_j}{\sqrt{d_k}}\right) = \frac{\exp\left(\frac{\boldsymbol{q}_i \cdot \boldsymbol{k}_j}{\sqrt{d_k}}\right)}{\sum_{j=1}^{n} \exp\left(\frac{\boldsymbol{q}_i \cdot \boldsymbol{k}_j}{\sqrt{d_k}}\right)}\]
ここで:
- \(\alpha_{ij}:単語iが単語jに注意を払う重み。\)
5. 重み付けされたバリューの計算
最後に、正規化された注意の重み(\(\alpha_{ij}\))を用いて、各単語のバリューベクトル(\(\boldsymbol{v}_j\))を重み付けし、全体を合計します:
\[\text{Attention Output}_i = \sum_{j=1}^{n} \alpha_{ij} \boldsymbol{v}_j\]
これにより、単語\(i\)が文中の他の単語から集約した情報が得られます。
6. Scaled Dot-Product Attentionの全体式
まとめると、Scaled Dot-Product Attentionは以下の式で表されます:
\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V\]
ここで:
- \(Q\):クエリ行列(\(\boldsymbol{q}_i\)の集合)。
- \(K\):キー行列(\(\boldsymbol{k}_j\)の集合)。
- \(V\):バリュー行列(\(\boldsymbol{v}_j\)の集合)。
3.3 Multi-Head Attentionの役割と設計
Scaled Dot-Product Attentionは、単一の注意メカニズムで単語間の関係を捉えます。しかし、文中にはさまざまな種類の関係性が存在するため、1つのAttentionだけでは不十分です。
Multi-Head Attentionの基本アイデア
Multi-Head Attentionは、複数の異なる「注意の視点」を同時に持つための仕組みです。以下の手順で実現されます:
- ヘッドごとに異なる重み行列を適用
各ヘッドで異なる重み行列(\(\boldsymbol{W}_Q, \boldsymbol{W}_K, \boldsymbol{W}_V\))を使用して、クエリ、キー、バリューを生成します。 - 複数のAttentionを計算
各ヘッドで独立にScaled Dot-Product Attentionを計算します。 - ヘッドの出力を結合
各ヘッドの出力を結合し、最終的に線形変換を行います。
以下に元となるGoogleの論文から図2を引用します。
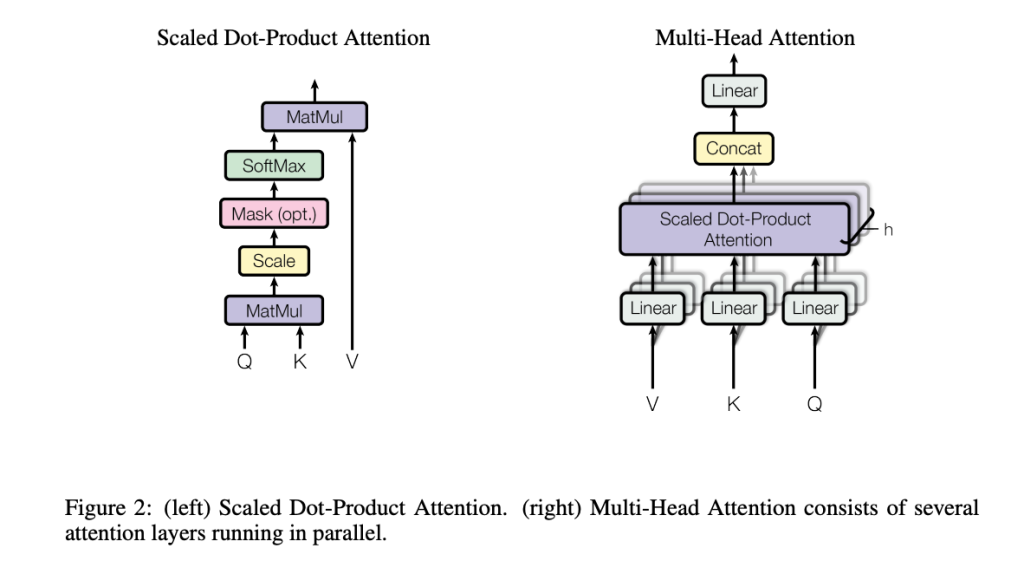
数学的表現
Multi-Head Attentionは次の式で定義されます:
\[\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h) \boldsymbol{W}_O\]
ここで:
- \(\text{head}_i = \text{Attention}(Q \boldsymbol{W}_Q^i, K \boldsymbol{W}_K^i, V \boldsymbol{W}_V^i)\)
- \(h\):ヘッドの数。
- \(\boldsymbol{W}_O\):結合後の線形変換用の重み行列。
3.4 Attentionの特徴とメリット
- 並列処理が可能
Attentionは全単語間の関連性を同時に計算するため、並列化が容易です。 - 長期依存関係のモデル化
文中の遠く離れた単語同士の関係も直接計算できます。 - 多様な関係性を捉える
Multi-Head Attentionにより、異なる種類の文脈依存性を同時に学習できます。
