AivisSpeech-engineをVPSで立ち上げてみた(1)
チャットボットを作っていると、「もう少し感情表現ができないかな?」と思うことがあります。
また、海外の音声合成サービスはどこか”違和感”を感じることがあります。
今回は、AivisProject様の合成音声がとても気になったので、チャットボットで使えるのか試してみたいと思いました。
Aivis Project
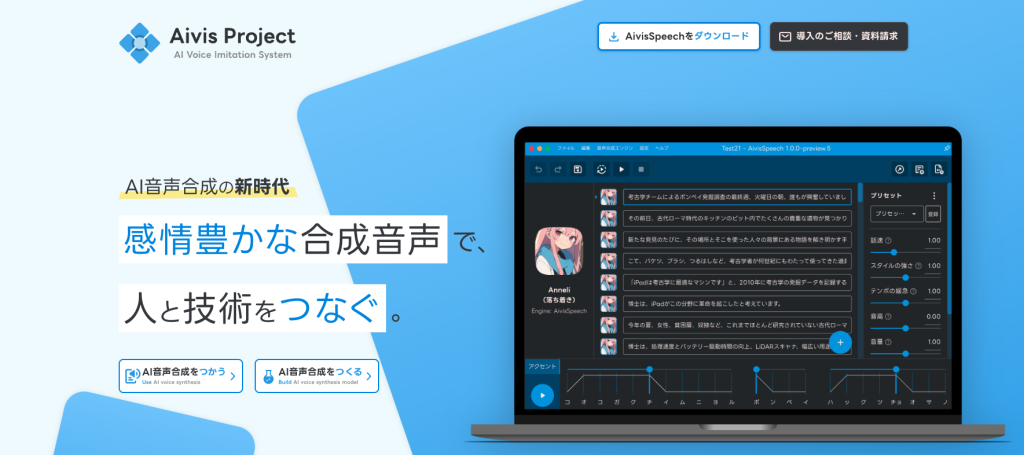
Aivis Project は、感情豊かな音声合成技術を誰もがかんたんに活用できる未来を目指す、
壮大な開発プロジェクトです。
機械的な響きに留まらない、まるで魂を宿したかのような音声が、あなたの想いや言葉に豊かな感情をのせて
世界へと響き渡る。Aivis Project が描く未来は、これまでにない感動と驚きに満ちています。好きなキャラクターの声で物語を紡ぎ、理想の声でニュース記事に命を吹き込む。
そうした新しい表現が、私たちのプロダクトを通じて数クリックで実現します。
AivisSpeech でのローカル音声合成から、モデルの制作・ミックス・公開まで、Aivis Project は
誰もが自由に好きな声を共有できる未来を形にしていきます。これまで一部の才能や特別な環境だけが手にできていた魅力的な声を、各々のアイデアや
想いを込めて、広く自由に使える未来へ。
あなたのアイデアや想いを、感動的な声で世界に届けてみませんか?— 2024年11月、Aivis Project の始動に寄せて
https://aivis-project.com/
音声合成モデルも自分で制作できるとのことなので、とても楽しみなプロジェクトです。
詳細は、公式ページhttps://aivis-project.comからご確認ください。
検証環境
今回使用したVPSの環境は以下の通りです:
- WebArena Indigo
- Ubuntu 22.04
- 6 CPU / 8 GB RAM
※時間単位での課金なので、検証環境として利用しやすいです。
CPUでも動作するということなので、安価に立ち上げられそうです。
セットアップ手順
1. Dockerのインストール
新規サーバーの場合、まずDockerをインストールします:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.shユーザーにDockerの実行権限を付与:
sudo usermod -aG docker $USER2. AivisSpeechの導入
CPU版のコンテナをpullして起動します:
docker pull ghcr.io/aivis-project/aivisspeech-engine:cpu-ubuntu20.04-1.1.0-devdocker run -d --restart unless-stopped -p 10101:10101 ghcr.io/aivis-project/aivisspeech-engine:cpu-ubuntu20.04-1.1.0-dev3. 動作確認
以下のコマンドで起動状態を確認できます:
curl http://localhost:10101/speakers正常に起動できていれば、利用可能な音声モデルのリストが表示されます。
音声合成の利用例
以下のPythonコードで、テキストから音声ファイルを生成できます:
このコードは、こちらのnoteから引用させていただきました。https://note.com/yuki_tech/n/n5bdbbc95b61b
import io
import json
import soundfile
import requests
class AivisAdapter:
def __init__(self):
# APIサーバーのエンドポイントURL
self.URL = "http://your-host:10101"
# 話者ID (話させたい音声モデルidに変更してください)
self.speaker = 888753760
def save_voice(self, text: str, output_filename: str = "output.wav"):
params = {"text": text, "speaker": self.speaker}
query_response = requests.post(f"{self.URL}/audio_query", params=params).json()
audio_response = requests.post(
f"{self.URL}/synthesis",
params={"speaker": self.speaker},
headers={"accept": "audio/wav", "Content-Type": "application/json"},
data=json.dumps(query_response),
)
with io.BytesIO(audio_response.content) as audio_stream:
data, rate = soundfile.read(audio_stream)
soundfile.write(output_filename, data, rate)
def main():
adapter = AivisAdapter()
while True:
text = input("> ")
if text.lower() == "q":
break
adapter.save_voice(text)
if __name__ == "__main__":
main()
このコードを実行すると、入力したテキストに対応する音声ファイルが生成されます。
まとめ
AivisSpeechはCPU環境でも動作可能なことがわかりました。導入自体は非常に簡単で、初心者でも気軽に試してみることができそうです。
ただ、今回の検証環境だと合成に少し時間がかかるようなので、チャットボットのようなリアルタイムの会話で利用するにはアプリ側での工夫が必要かもしれません。
次はチャットボットに組み込んでみたいと思います。

