日本語大規模言語モデル(LLM)rinnaを使ってみる
rinna株式会社様が日本語に特化したGPTモデルをオープンソースで公開してくださいました。早速試してみたいと思います。
[blogcard url=https://rinna.co.jp/news/2023/05/20220531.html]
rinnaの日本語に特化した強化学習済み対話GPT言語モデルの特徴
・36億パラメータを持つ汎用GPT言語モデルをベースに、対話GPT言語モデルへのfine-tuningと強化学習を行っています。
・強化学習には、HH-RLHFの一部を日本語に翻訳したデータを用いています。
・強化学習済みのモデルは、Hugging Faceに商用利用可能なMIT Licenseで公開されています。
・特定の利用目的に対して性能を最適化させたい場合には、fine-tuningやin-context learningにより精度向上を目指すことができます。
・強化学習済みと強化学習前の対話GPT言語モデルの性能を、人間による評価とChatGPTによる自動評価で比較しました。人間による評価では、強化学習済みの返答が良いが47%、差がないが31%、悪いが22%となり、ChatGPTによる自動評価では、強化学習済みの返答が良いが63%、差がないが3%、悪いが34%となりました。両評価手法で、人間の評価を利用した強化学習による性能向上が確認されました。
汎用言語モデル(rinna/japanese-gpt-neox-3.6b)と、強化学習された対話用のGPT言語モデル(rinna/japanese-gpt-neox-3.6b-instruction-sft-v2)は、どちらも商用利用可能なMITライセンスで公開されています。
gpt-neoxは、EleutherAIという非営利の人工知能研究グループが開発したGPTモデルで、OpenAIのGPTモデルのオープンソース版とみなされています。
rinnaもこのEleutherAIのgpt-neoxをベースにトレーニングされています。
モデルの規模を表すパラメータ数は36億パラメータで、ChatGPTの1750億パラメータ、PaLMの5400億パラメータに比べると小さいものですが、必要なコンピュータ資源も小さくて済むという利点もあります。
Hugging Face Inference Endpoints
手っ取り早く、サーバを立てるのに以前紹介したHugging FaceのInference Endpointsを使ってみます。
[blogcard url =https://nagomi-informal.net/archives/1089]
前回はrinna/japanese-gpt2-smallを使って試しました。その時には、CPUでも動作可能だったのですが、今回は、最低でもGPU[medium]が必要でした。
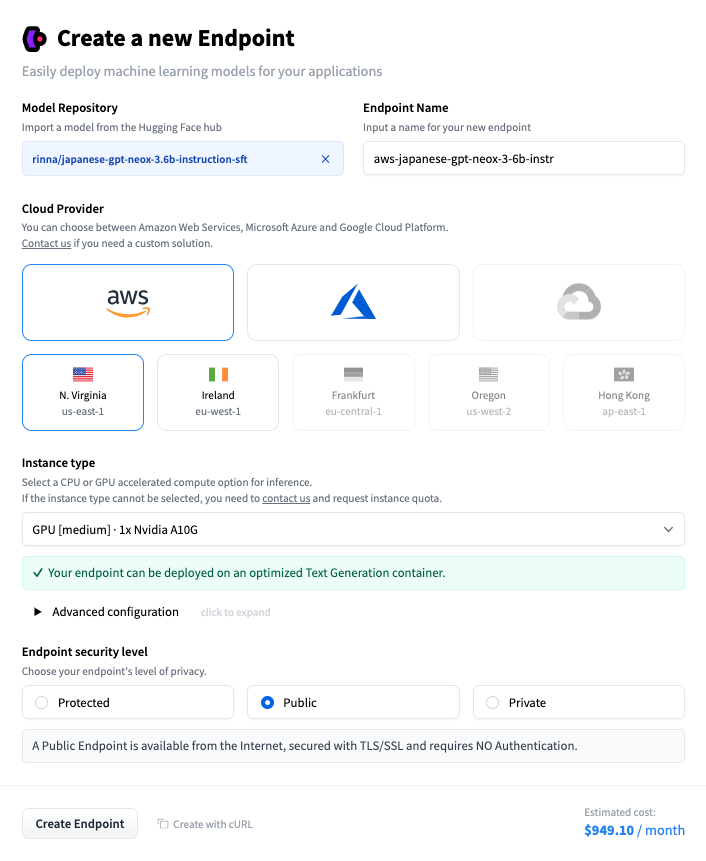
その結果、$949.10/month(約132,000円)にもなってしまい、簡単には使えない金額になってしまいました。
Google Colabratory
クラウドサーバでGPUを使うと、高額になってしまうので、諦めてGoogle Colabを使います。
こちらも、無料版ではメモリが足りなくなってしまいました。そこでColab Pro(月額 ¥1,179)にアップグレードします。
ランタイムのタイプを変更からTPUとハイメモリを選択します。

必要なライブラリをインストールして、サンプルを動作させてみます。
!pip install transformers
!pip install sentencepieceprompt = [
{
"speaker": "ユーザー",
"text": "日本のおすすめの観光地を教えてください。"
},
{
"speaker": "システム",
"text": "どの地域の観光地が知りたいですか?"
},
{
"speaker": "ユーザー",
"text": "渋谷の観光地を教えてください。"
}
]
prompt = [
f"{uttr['speaker']}: {uttr['text']}"
for uttr in prompt
]
prompt = "<NL>".join(prompt)
prompt = (
prompt
+ "<NL>"
+ "システム: "
)
print(prompt)
# "ユーザー: 日本のおすすめの観光地を教えてください。<NL>システム: どの地域の観光地が知りたいですか?<NL>ユーザー: 渋谷の観光地を教えてください。<NL>システム: "
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("rinna/japanese-gpt-neox-3.6b-instruction-sft")
if torch.cuda.is_available():
model = model.to("cuda")
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)最初のモデルの読み込みには、数分かかりますが、推論自体は数秒程度で応答が返ってきます。
会話を続けるためには、promptを再構成して、tokenizer.encode以下を実行します。例えば、最初にモデルを読み込んだ後に、以下のようなセルでuserメッセージを入力しながら、会話を続けることができます。
user = "" #@param {type:"string"}
prompt =prompt + "ユーザー: "+user+"<NL>システム: "
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=128,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)
output = output.replace("</s>","")
prompt = prompt + output + "<NL>"
print(prompt)まとめ
今回発表されたrinnaは、ChatGPTとは用途がかなり異なるものかと思います。ニュースリリースの特徴にも書かれているように、特定用途向けにfine-tuningやin-context learningにより精度向上を目指すことができること、比較的小規模の推論サーバで実行できることなどがメリットかと思います。
また、株式会社rinna様が提供している各種APIもあります。月間1,000リクエストは無料で使えるようです。公開されているAPIと今回のモデルとの関係がまだ十分に理解できていないのですが、引き続き試していきたいと思います。
