Transformerの仕組みを体系的に理解したい 第4章
第4章: Transformerの全体構造
前章では、Transformerの核となるAttention機構について記述しました。
Transformerの仕組みを体系的に理解したい 第3章
第3章: Attention機構の仕組み Transformerの革新の中心となるのがAttention機構です。特に、Self-Attention(自己注意メカニズム)は、入力文中の単語間の関係をモデル化…

この章では、Transformer全体の構造を記述していきます。特に、エンコーダーとデコーダーの役割や相互作用、各構成要素の詳細について、翻訳タスクの例と質問応答タスクの例を用いて、その動作を具体的に記述してみます。
4.1 Transformerの全体構造
Transformerは、大きく分けて以下の2つの部分で構成されています:
- エンコーダー(Encoder)
- 入力文を受け取り、その意味的な特徴(中間表現)を学習します。
- 複数のエンコーダ層をスタックして構成されます。
- デコーダー(Decoder)
- エンコーダで得られた中間表現を参照しながら、出力文(または答え)を逐次生成します。
- 複数のデコーダ層をスタックして構成されます。
Transformer全体の構造は、Googleが2017年に発表した論文「Attention Is All You Need」で、以下の図のように表されます。
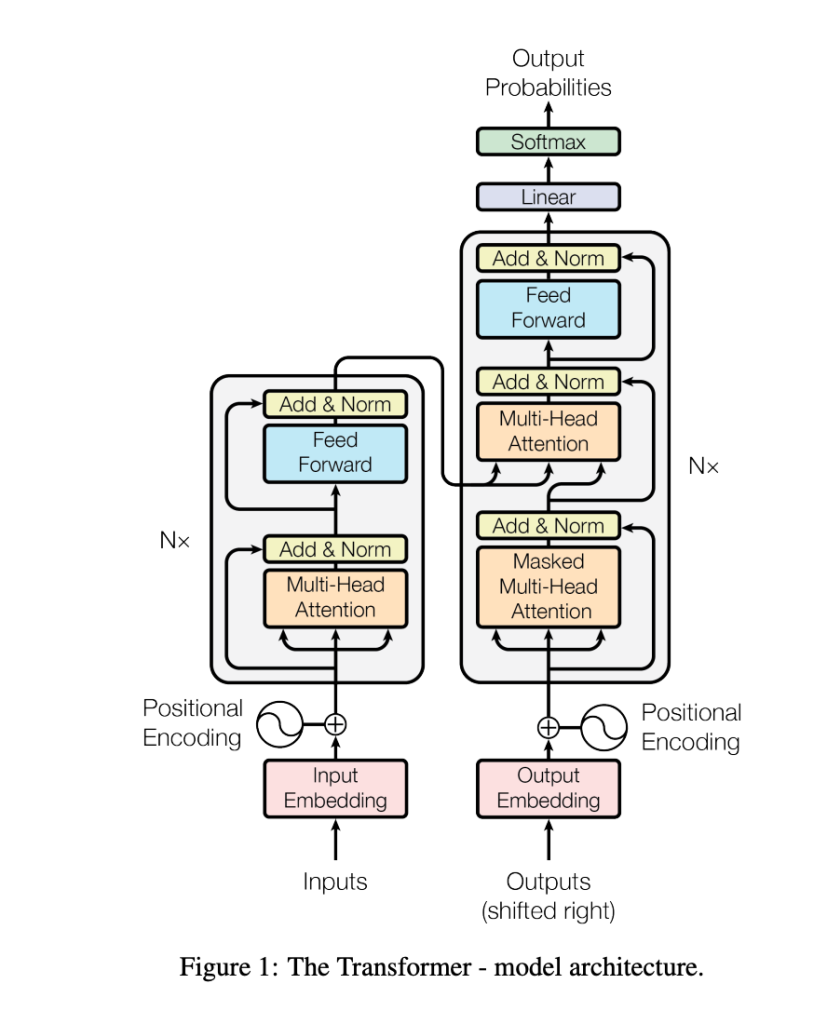
4.2 エンコーダーの詳細構造
エンコーダーは、複数のエンコーダーブロックから構成され、それぞれのブロックが以下の2つの主要なサブ層を持っています:
- マルチヘッドSelf-Attention層
- 入力文中の各単語が、他の単語とどのような関係を持つかを計算します。
- Self-Attentionは、入力文全体の情報を集約する仕組みです。
- フィードフォワードネットワーク(FFN)
- Attentionの出力をさらに変換し、高次元の特徴を抽出します。
- 全結合層(Fully Connected Layer)を使用します。
エンコーダーの計算の流れ
- 単語埋め込みと位置エンコーディング
入力文をトークン化し、各トークンを埋め込みベクトルに変換します。さらに位置エンコーディングを加算します: \[\text{Input Embedding} = \text{Word Embedding} + \text{Positional Encoding}\] - マルチヘッドSelf-Attention
各単語の特徴を、他のすべての単語との関係から再計算します。この出力は次のように表されます: \[\text{Self-Attention Output} = \text{MultiHead}(Q, K, V)\] - 残差接続と正規化(Layer Normalization)
Attentionの出力に、入力をそのまま加算して残差接続を行い、その後Layer Normalizationを適用します: \[\text{Output} = \text{LayerNorm}(\text{Input} + \text{Self-Attention Output})\] - フィードフォワードネットワーク(FFN)
正規化された出力をフィードフォワードネットワークに通し、非線形変換を行います:\[ \text{FFN}(x) = \text{ReLU}(xW_1 + b_1)W_2 + b_2\] - 再び残差接続と正規化
フィードフォワードネットワークの出力に、入力を加算して正規化します。 - 次のエンコーダーブロックへ
この処理を複数回繰り返し、最終的に入力文全体の高度な特徴ベクトルを出力します。
4.3 デコーダーの詳細構造
デコーダーもエンコーダーと同様に複数のデコーダーブロックで構成されており、各ブロックに以下の3つのサブ層があります:
- マルチヘッドSelf-Attention層
- デコーダー自身の出力(部分的に生成されたターゲット文)を基に、それぞれのトークンが他のトークンとどのような関係にあるかを計算します。
- Future Masking(未来の単語を遮断)を適用します。
- エンコーダー-デコーダーAttention層
- エンコーダーの出力を基に、入力文とターゲット文間の関係を計算します。
- 翻訳タスクなどで重要な役割を果たします。
- フィードフォワードネットワーク(FFN)
- エンコーダーとデコーダー間で得られた情報をさらに処理します。
デコーダーの計算の流れ
- ターゲット文の入力と位置エンコーディング
ターゲット文をトークン化し、単語埋め込みと位置エンコーディングを加算します。 - Masked Self-Attention
部分的に生成されたターゲット文を基に、各トークン間の関係を計算します。Future Maskingにより、未来の単語(まだ生成されていない部分)を遮断します。 - エンコーダー-デコーダーAttention
エンコーダーの出力とデコーダーの中間出力を入力に、ターゲット文と入力文間の関連性を計算します。 - フィードフォワードネットワーク(FFN)
Attentionの出力をさらに変換し、非線形な特徴を抽出します。 - 残差接続と正規化
各サブ層の出力に残差接続を適用し、Layer Normalizationを行います。 - 次のデコーダーブロックへ
この処理を複数回繰り返し、最終的にターゲット文に対応する特徴ベクトルを出力します。
4.4 エンコーダーとデコーダーの相互作用
Transformerにおけるエンコーダーとデコーダーの相互作用は、主にエンコーダー-デコーダーAttentionを通じて行われます。
- エンコーダーの出力
エンコーダーは、入力文全体を要約した特徴ベクトルを出力します。 - エンコーダー-デコーダーAttention
デコーダーでは、この特徴ベクトルを参照しながら、ターゲット文を生成します。具体的には、エンコーダーの出力を「キー」と「バリュー」として使用し、デコーダー自身の中間出力を「クエリ」として使用します。
4.5 Transformerの出力層
Transformerの最後の出力層では、デコーダーの最終的な出力を用いてターゲット文を生成します。具体的には:
- 線形変換
デコーダーの出力(特徴ベクトル)を、語彙サイズと同じ次元数に変換します。 - Softmax関数
線形変換後の出力をSoftmax関数に通し、各単語の出現確率を計算します。 - 次の単語を選択
最も確率の高い単語を選択し、次のトークンとして使用します。
